Blog
Conseils, guides et analyses sur les collègues IA, un support plus intelligent et la construction de meilleures équipes.


Les 8 meilleures applications d'automatisation IA pour Freshdesk en 2026
Nous avons testé huit applications d'automatisation IA pour Freshdesk en 2026 — de Freddy AI natif aux agents helpdesk-agnostiques comme eesel, Forethought et Ada — avec les vrais tarifs et nos verdicts.

Les 8 meilleurs agents IA pour le service client en 2026
Un aperçu concret des meilleurs agents IA pour le service client en 2026 - ce que chacun fait vraiment, pour qui il est conçu, et comment les tarifs fonctionnent réellement.
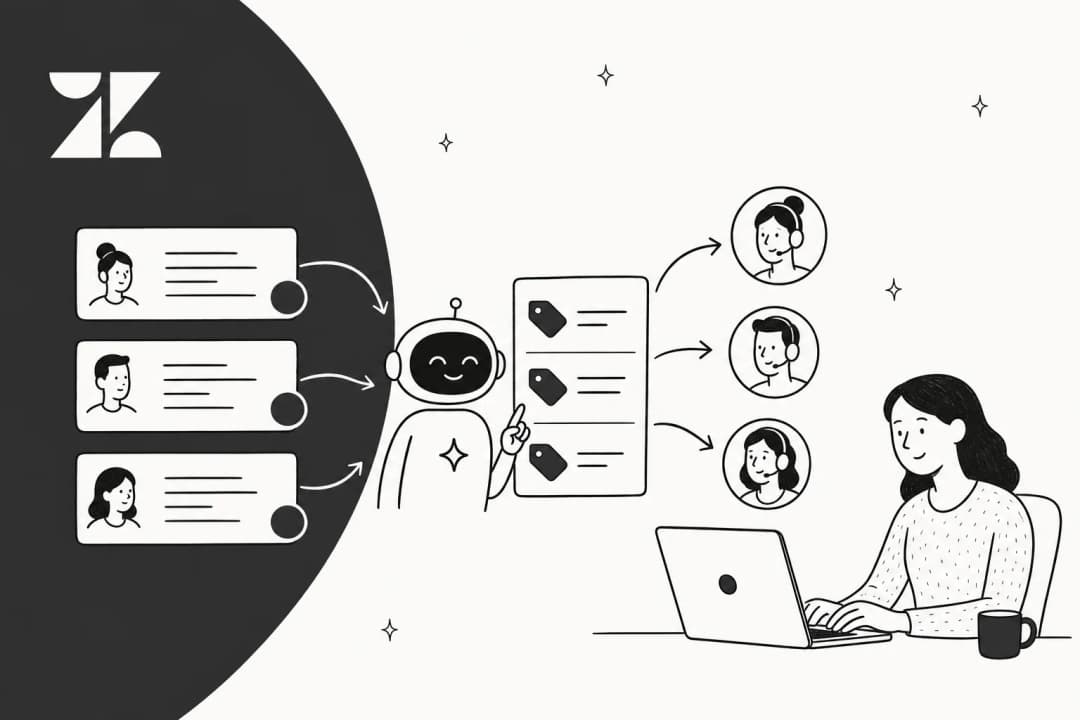
Automatiser le marquage des tickets Zendesk avec l'IA : un guide pratique
Un guide complet et sans détour sur l'automatisation du marquage des tickets Zendesk - déclencheurs natifs, Triage Intelligent, et agents IA - avec les compromis clairement exposés.

Comment automatiser le support client sans tout casser : un guide pratique 2026
Un guide concret pour automatiser le support client en 2026 : la pile à six couches, le piège du taux de déviation, les vrais chiffres de coûts, et un déploiement en 5 étapes qui passe en production sans brûler vos clients.

Atlassian intègre un assistant IA dans Jira et Confluence : bilan réaliste 2026
Atlassian a intégré un assistant IA dans Jira et Confluence avec Atlassian Intelligence et Rovo. Voici ce qu'il fait réellement, ce qu'il coûte et ses limites.

Comparaison des outils de rédaction IA en 2026 : 8 plateformes testées côte à côte
Une comparaison honnête et côte à côte de huit outils de rédaction IA en 2026 - Jasper, Copy.ai, Writer, Writesonic, Anyword, Koala, Frase et Rytr - avec de vrais tarifs, de vraies avis, et un verdict pour chacun.

IA vs support client humain : là où chacun gagne vraiment (et le modèle hybride qui surpasse les deux)
L'IA gère les tickets de niveau 1 à 0,50 $ pièce, tandis que les humains coûtent 8 à 12 $. Le point de vue honnête sur là où chacun gagne, et le modèle hybride qui surpasse silencieusement les deux approches seules.

J'ai testé 10 outils IA pour le service client en 2026 - voici ce qui fonctionne vraiment
Un tour d'horizon honnête des 10 outils IA pour le service client qui méritent d'être présélectionnés en 2026, à qui chacun s'adresse réellement, et ce qu'ils coûtent vraiment.

J'ai testé 8 des meilleurs outils IA pour le marketing de contenu en 2026
Un guide pratique sur les 8 outils IA pour le marketing de contenu qui méritent vraiment une place dans votre stack en 2026 - des moteurs de blog SEO de la recherche à la publication aux éditeurs de voix de marque.
Prêt à recruter votre collègue IA ?
Configuration en quelques minutes. Pas de carte bancaire requise.