
Alors, vous avez configuré une IA pour vous aider avec l'étiquetage des tickets. Le rêve, c'était une file d'attente parfaitement organisée où chaque problème client est trié automatiquement. La réalité ? Eh bien, c'est peut-être un peu le bazar. Lorsque votre IA commence à coller les mauvaises étiquettes sur les tickets, ce n'est pas juste un petit contretemps, c'est la recette du chaos. Vous vous retrouvez avec des tickets mal acheminés, des agents qui perdent du temps à corriger les erreurs de l'IA, et des clients qui attendent plus longtemps pour obtenir une réponse.
Ce guide est un plan d'action simple pour comprendre pourquoi votre IA se trompe et comment y remédier. Nous verrons comment nettoyer vos données, décider à quoi ressemble un résultat « suffisamment bon », et utiliser les bons outils pour construire un système d'étiquetage auquel vous n'aurez pas à constamment douter.
Ce dont vous aurez besoin pour commencer
Avant de nous lancer dans les corrections, assurons-nous que vous avez quelques éléments à portée de main. Pas besoin d'un doctorat en science des données, mais avoir les bonnes informations et les bons outils fait toute la différence.
-
L'historique de votre service d'assistance : Vous aurez besoin d'un accès à un backlog de tickets de votre plateforme, que ce soit Zendesk, Freshdesk, ou autre. C'est là que vous trouverez les schémas récurrents.
-
Un outil d'IA que vous pouvez réellement contrôler : Si votre IA est une « boîte noire » sans paramètres à ajuster, les accidents vont se compliquer. Vous avez besoin d'un outil qui vous permet d'affiner son comportement.
-
Une idée claire de vos objectifs : Pourquoi utilisez-vous ces étiquettes en premier lieu ? Sont-elles destinées à l'acheminement des tickets, à la détection des problèmes urgents, ou à la création de rapports sur les bugs ? Connaître le « pourquoi » représente la moitié du travail.
-
Une compréhension de base de la précision : Vous ne pouvez pas réparer ce que vous ne pouvez pas mesurer. Nous aborderons la simple différence entre privilégier moins de mauvaises étiquettes (précision) et attraper chaque ticket pertinent (rappel).
Étape par étape : Comment réduire les faux positifs de l'IA dans l'étiquetage de tickets
Bon, mettons les mains dans le cambouis. Corriger les faux positifs est plus un processus de réglage qu'une solution miracle. Suivez ces étapes pour rendre votre étiquetage par IA plus fiable.
Étape 1 : Définissez ce qu'un « faux positif » signifie pour votre équipe
Le terme « faux positif » peut sembler un peu technique, mais pour une équipe de support, c'est un véritable casse-tête. C'est simplement lorsque l'IA attribue la mauvaise étiquette à un ticket. Avant de pouvoir réduire ces erreurs, votre équipe doit se mettre d'accord sur celles qui sont les plus préjudiciables.
Par exemple, un faux positif pourrait être :
-
Une simple question de tarification est étiquetée comme « Demande de remboursement », l'envoyant à la mauvaise équipe et provoquant un léger vent de panique.
-
Une idée de fonctionnalité suggérée de manière informelle est étiquetée « Bug Urgent », détournant les développeurs des véritables urgences.
-
Le problème de connexion d'un nouveau client est marqué comme « Spam », ce qui est une première impression plutôt désastreuse.
Votre première action est de vous réunir et de lister les 5 à 10 erreurs d'étiquetage qui causent le plus de problèmes. Cela vous donne une cible claire. Une bonne plateforme d'IA devrait rendre ces erreurs faciles à repérer. Par exemple, un outil comme eesel AI vous permet de lancer une simulation sur vos tickets passés. Cela vous montre exactement comment l'IA les aurait étiquetés, vous permettant de détecter ce genre d'erreurs avant même de la lâcher sur des conversations client en direct.
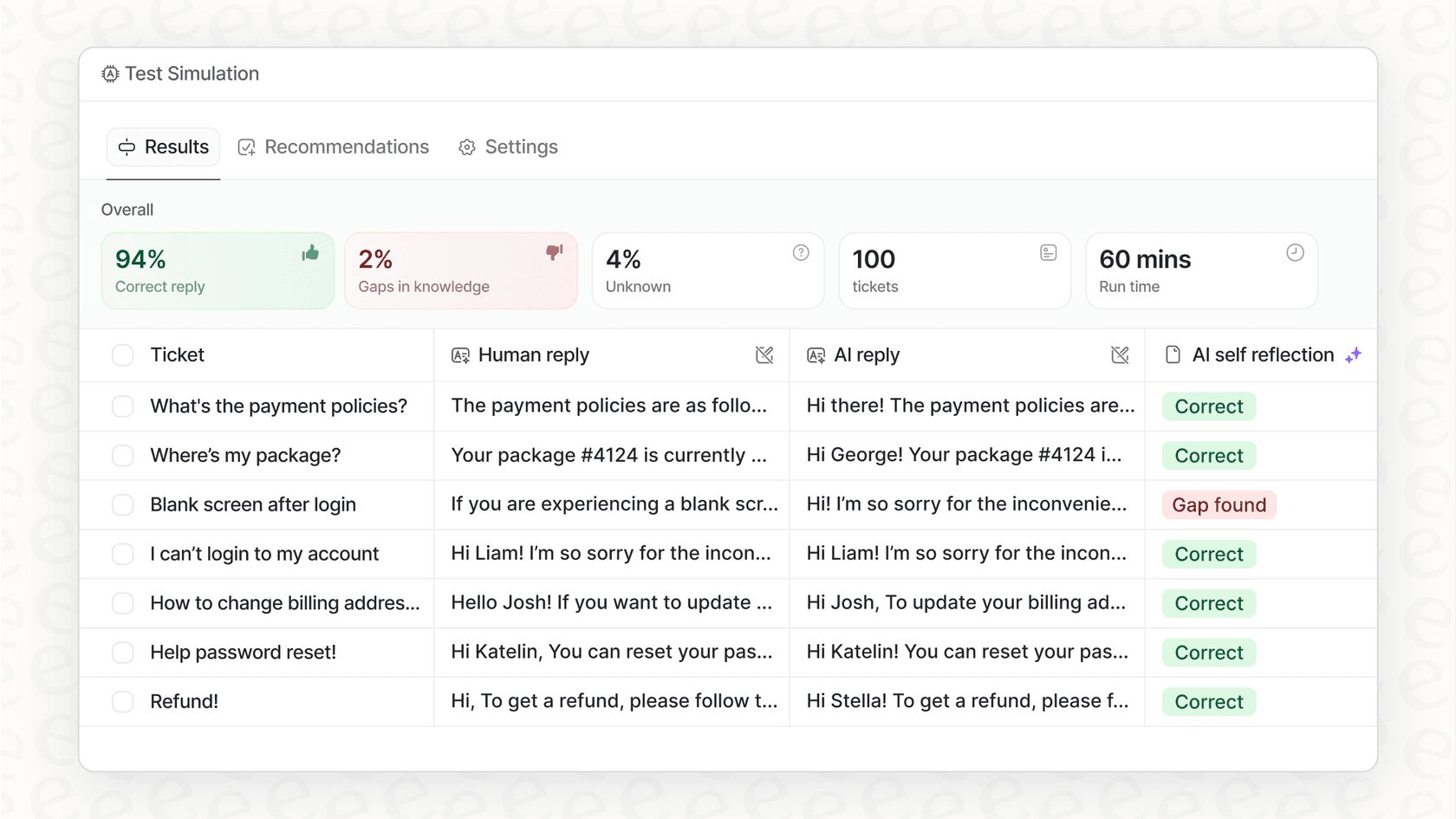
Étape 2 : Analysez vos sources de connaissances pour détecter les conflits et les lacunes
Considérez votre IA comme un nouveau stagiaire. Si vous lui donnez une pile de manuels de formation confus, obsolètes ou contradictoires, ne soyez pas surpris s'il fait des erreurs. La performance de votre IA est le reflet direct des données à partir desquelles elle apprend, et les faux positifs sont souvent le signe que son « cerveau » est un peu encombré.
Voici un bilan de santé rapide que vous pouvez effectuer sur les connaissances de votre IA :
-
Examinez votre centre d'aide public : Avez-vous des articles contenant des informations contradictoires, comme une ancienne page de tarification qui traîne encore ? Certaines instructions sont-elles tout simplement confuses ?
-
Vérifiez vos documents internes : Qu'en est-il de vos macros, réponses pré-enregistrées et wikis internes ? Les agents sont-ils tous sur la même longueur d'onde, ou chacun fait-il les choses à sa manière ?
-
Plongez dans les anciens tickets : C'est là que la vraie magie opère. Voyez comment vos agents humains ont appliqué les étiquettes. Vous y trouverez souvent des règles non écrites et des incohérences que votre IA a essayé d'apprendre.
L'idée de nettoyer manuellement des années de connaissances accumulées a de quoi décourager n'importe qui. C'est un projet énorme et une raison courante pour laquelle les équipes se retrouvent bloquées. C'est là que les nouveaux outils d'IA peuvent vous faire gagner un temps précieux. Au lieu de vous laisser faire tout le gros du travail, une plateforme comme eesel AI peut se connecter à toutes vos différentes sources de connaissances, de Confluence et Google Docs aux conversations de tickets passés, et les unifier automatiquement. Elle peut même repérer les lacunes dans votre documentation et vous aider à rédiger de nouveaux articles en se basant sur ce qu'elle apprend des tickets résolus avec succès, ce qui aide l'IA à améliorer sa propre matière première au fil du temps.
Étape 3 : Utilisez la précision et le rappel pour définir les bons objectifs de performance
Pas besoin d'être un statisticien pour bien faire les choses. Tout se résume à une question simple : quel type d'erreur est le pire pour nous ?
-
Se concentrer sur la Précision (Moins de Faux Positifs) : C'est comme le filtre anti-spam de votre messagerie. Vous préféreriez probablement qu'un spam se glisse dans votre boîte de réception (un manqué) plutôt qu'un e-mail important de votre patron se retrouve enterré dans le dossier spam (un faux positif). Pour les étiquettes critiques comme « Erreur de facturation » ou « Problème de sécurité », vous avez besoin d'une haute précision. Lorsque l'IA utilise ces étiquettes, elle a intérêt à avoir raison.
-
Se concentrer sur le Rappel (Attraper Tous les Cas Potentiels) : Maintenant, pensez à la détection de fraude d'une banque. Elle préférerait de loin signaler un achat légitime par erreur et vous demander de le confirmer (un faux positif) plutôt que de laisser passer une transaction frauduleuse (un manqué). Pour des étiquettes comme « Risque de résiliation » ou « Client VIP », vous pourriez vouloir que l'IA soit un peu trop prudente, même si cela signifie que les agents doivent corriger quelques signalements incorrects. Manquer ne serait-ce qu'un seul de ces tickets coûte trop cher.
Votre prochaine tâche est de classer vos étiquettes les plus importantes dans deux catégories : « Haute Précision Requise » et « Haut Rappel Requis ». Cet exercice simple vous aide à indiquer à votre système d'IA ce qui compte le plus pour vous.
Étape 4 : Affinez votre IA avec de meilleures instructions et des connaissances délimitées
Une fois que vous connaissez vos objectifs, vous pouvez commencer à donner de meilleures instructions à votre IA. De nombreux systèmes d'IA échouent parce qu'ils sont des boîtes noires ; vous entrez des données, des étiquettes sortent, et vous n'avez aucune idée pourquoi. Pour réellement réduire les faux positifs, vous devez être aux commandes.
C'est là qu'avoir un flux de travail personnalisable fait une énorme différence. Au lieu d'être coincé avec un modèle universel, une plateforme comme eesel AI vous permet de prendre le contrôle.
-
Personnalisez l'invite : Vous pouvez utiliser un éditeur simple pour dire à l'IA exactement ce que chaque étiquette signifie. Donnez-lui des exemples. Donnez-lui des règles pour savoir quand ne pas utiliser une étiquette. Par exemple : « Ne pas étiqueter un ticket comme 'Urgent' à moins que le client n'utilise des mots comme 'panne', 'interruption' ou 'ne peut pas accéder'. »
-
Délimitez la connaissance : C'est un levier énorme pour améliorer la précision. Vous pouvez dire à l'IA d'utiliser uniquement un ensemble spécifique d'articles pour certains sujets. Pour une question de facturation, vous pouvez restreindre l'IA à vos cinq articles de facturation officiels et rien d'autre. Cela l'empêche d'être désorientée par des informations anciennes ou non pertinentes et réduit considérablement les erreurs.
-
Contrôlez le déploiement : Vous n'avez pas besoin de tout miser d'un coup. Commencez par laisser l'IA étiqueter les tickets pour une seule équipe ou sur un seul sujet. Cela vous permet de gagner en confiance et de prouver que cela fonctionne avant de l'étendre.
Ce type de contrôle rend le comportement de l'IA prévisible et fiable car elle fonctionne dans le cadre que vous avez défini.

Testez votre IA avant qu'elle ne touche à un seul ticket client
La plus grande crainte avec toute nouvelle automatisation est qu'elle déraille sous les yeux de vos clients. Alors, comment pouvez-vous être sûr que votre IA soigneusement réglée ne commencera pas à faire des erreurs étranges sur les tickets en direct ? La réponse : la simulation.
Au lieu d'activer simplement l'IA et d'espérer que tout se passe bien, vous devriez pouvoir la tester dans un environnement sûr. Cela signifie exécuter votre configuration d'IA sur vos données de tickets historiques pour voir exactement ce qu'elle aurait fait. C'est l'ultime vérification avant le décollage.
C'est une fonctionnalité majeure à rechercher dans une plateforme d'IA. Alors que certains outils proposent des démos vagues, eesel AI dispose d'un puissant mode de simulation qui vous donne de vraies données sur lesquelles travailler. Voici à quoi cela ressemble en pratique :
-
Testez sur vos propres données : Vous lancez la simulation sur des milliers de vos propres tickets passés, pas sur des exemples génériques.
-
Obtenez un bulletin de notes détaillé : Le rapport de simulation vous montre exactement comment l'IA aurait étiqueté chaque ticket, en signalant les faux positifs potentiels et en calculant un score de performance réaliste.
-
Lancez-vous en toute confiance : Armé d'une prévision précise de votre taux d'automatisation et de votre précision, vous pouvez activer l'IA en sachant exactement à quoi vous attendre.
La simulation élimine la part d'incertitude de l'équation et vous permet de prendre des décisions basées sur des données, pas sur de l'espoir.

Erreurs courantes à éviter
Au fur et à mesure que vous suivez ces étapes, gardez un œil sur quelques pièges courants qui peuvent vous faire trébucher.
-
Le configurer et l'oublier : Vos produits changent, tout comme les problèmes de vos clients. Un modèle d'IA peut « dériver » avec le temps et devenir moins précis. Vous avez besoin d'un processus simple pour vérifier et réajuster le modèle de temps en temps.
-
N'utiliser que votre base de connaissances officielle : Certaines des meilleures informations sont cachées dans les conversations passées entre agents et clients. Si vous ignorez cette mine d'or de contexte du monde réel, vous sacrifiez de la précision.
-
Essayer de tout automatiser en une seule fois : Ne visez pas 100 % d'automatisation dès le premier jour. Choisissez un ou deux types de tickets faciles à définir, automatisez-les avec succès, puis étendez à partir de là. Un déploiement progressif est la clé du succès.
Le moyen le plus rapide d'obtenir un étiquetage de tickets par IA précis
Réduire les faux positifs de l'IA ne consiste pas à trouver un algorithme « parfait ». Il s'agit d'avoir le bon processus et les bons outils. Le processus est simple : déterminez quelles sont vos pires erreurs, nettoyez et concentrez vos données, fixez des objectifs clairs et testez tout avant de vous lancer. Les bons outils sont ceux qui rendent ce processus facile, vous donnant le contrôle sur la logique de l'IA et un moyen sans risque de simuler ses performances.
Lorsque vous combinez un processus intelligent avec un outil flexible, vous pouvez enfin obtenir les avantages de l'automatisation du support sans tout le bruit parasite.
Démarrez avec eesel AI
Avec eesel AI, vous pouvez être opérationnel en quelques minutes, simuler les résultats sur vos propres données et utiliser notre moteur de flux de travail pour obtenir un contrôle total sur l'étiquetage de vos tickets. Vous pouvez commencer petit, prouver la valeur et monter en puissance lorsque vous êtes prêt.
Prêt à cesser de traquer les faux positifs et à commencer à automatiser en toute confiance ? Commencez votre essai gratuit d'eesel AI dès aujourd'hui et voyez comment il se comporte sur vos tickets.
Foire aux questions
L'étape initiale consiste à définir clairement ce qu'un « faux positif » signifie pour votre équipe spécifique et à identifier les 5 à 10 erreurs d'étiquetage qui causent les problèmes les plus importants. Cela fournit une cible claire pour l'amélioration.
La précision se concentre sur la minimisation des étiquettes incorrectes (faux positifs), garantissant que lorsqu'une étiquette est appliquée, il est très probable qu'elle soit correcte. Le rappel, d'autre part, vise à attraper tous les tickets pertinents pour une étiquette spécifique, même si cela signifie quelques faux positifs. Comprendre quel type d'erreur est le plus préjudiciable pour une étiquette donnée vous aide à prioriser et à affiner le comportement de votre IA.
Vous pouvez affiner votre IA en personnalisant ses invites avec des règles et des exemples spécifiques pour chaque étiquette, et en délimitant ses connaissances. Délimiter signifie restreindre l'IA à n'utiliser qu'un sous-ensemble très pertinent d'articles pour certains sujets, évitant ainsi la confusion due à des informations non pertinentes.
La méthode la plus efficace consiste à utiliser un mode de simulation au sein de votre plateforme d'IA pour la [tester sur vos propres données de tickets historiques](https://panther.com/blog/identifying-and-mitigating-false-positive-alerts). Cela vous permet de voir exactement comment l'IA aurait étiqueté les tickets passés, d'identifier les faux positifs potentiels et d'évaluer sa précision avant qu'elle n'interagisse avec des conversations client en direct.
Il est crucial d'éviter une mentalité de « configurer et oublier ». Examinez régulièrement les performances de votre IA, car les produits et les problèmes des clients évoluent. Réajuster périodiquement le modèle et analyser les nouvelles données de tickets aidera à maintenir la précision et à s'adapter aux changements, prévenant ainsi la dérive du modèle.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.
Votre IA apprend à partir de vos données existantes, donc nettoyer les informations contradictoires ou obsolètes, et analyser comment les [agents humains ont utilisé les étiquettes](https://www.eesel.ai/fr/blog/zendesk-ai-ticket-classification-complete-rundown-in-2025) dans les anciens tickets, améliore directement la qualité de son matériel d'apprentissage. Ces données affinées aident l'IA à prendre des décisions d'étiquetage plus précises.