
L'API Realtime d'OpenAI fait beaucoup de bruit, et honnêtement, c'est compréhensible. L'idée de créer des agents vocaux ultra-réactifs et à l'intonation humaine est plutôt excitante. Le modèle qui attire le plus l'attention est le « gpt-4o-mini-realtime », principalement parce qu'il promet des performances solides à un prix qui semble dérisoire.
Mais voilà le hic. Dès que vous consultez la page des tarifs, vous êtes bombardé de jargon comme « par million de tokens » pour le texte, l'audio et quelque chose appelé les entrées en cache. La plupart d'entre nous se grattent la tête et se posent la même question : « D'accord, mais combien ça me coûte réellement à la minute ? »
Si vous essayez de déterminer la viabilité d'un projet ou simplement d'établir un budget, la tarification basée sur les tokens est un véritable casse-tête. Nous avons donc décidé de faire le calcul pour vous. Ce guide décortique le coût réel de l'utilisation de GPT Realtime Mini, révélant les facteurs cachés qui peuvent faire exploser vos dépenses au moment où vous vous y attendez le moins.
Comprendre l'API Realtime d'OpenAI
Avant de nous plonger dans les chiffres, mettons-nous d'accord. L'API Realtime d'OpenAI est un outil pour les développeurs qui souhaitent créer des applications avec des conversations vocales rapides. En gros, elle vous permet de créer une IA capable d'écouter et de répondre quasi instantanément, sans le décalage gênant que l'on retrouve avec les anciennes technologies.
Elle est conçue pour alimenter des agents vocaux. Imaginez une IA capable de gérer les appels du service client, de prendre des rendez-vous ou de répondre aux questions internes de votre équipe, tout en ayant l'air naturelle.
L'API vous propose plusieurs modèles. Il y a le puissant « gpt-4o-realtime » pour les discussions plus complexes, et son petit frère moins cher et plus rapide, « gpt-4o-mini-realtime ». Nous nous concentrons ici sur la version mini, car son prix d'appel en fait le point de départ de prédilection pour beaucoup de monde.
Le problème avec la tarification par token d'OpenAI
OpenAI vous facture pour chaque « token » que votre application utilise. Un token n'est qu'un minuscule morceau de donnée : il peut s'agir d'un mot, d'une syllabe ou d'un fragment audio. Le coût est basé sur le nombre de tokens que vous envoyez au modèle (entrée) et le nombre qu'il vous renvoie (sortie).
Voici la tarification officielle de GPT Realtime Mini, tirée de la page de tarification d'OpenAI :
| Modèle et type de token | Prix d'entrée (par million de tokens) | Prix de sortie (par million de tokens) |
|---|---|---|
| gpt-4o-mini-realtime-preview | ||
| Texte | 0,60 $ | 2,40 $ |
| Audio | 10,00 $ | 20,00 $ |
| Entrée audio en cache | 0,30 $ | N/A |
Ces chiffres semblent minuscules, n'est-ce pas ? Mais ce modèle rend la prévision de vos coûts incroyablement difficile pour plusieurs raisons :
-
La durée des appels est très variable. Une conversation rapide d'une minute utilise beaucoup moins de tokens qu'un appel d'assistance complexe de dix minutes. Comment prédire la moyenne ?
-
Le rapport entrée/sortie change. Un client bavard et une IA silencieuse coûteront moins cher qu'un client silencieux qui a besoin de longues explications détaillées de la part de l'IA.
-
Les prompts système : le coût caché. C'est le plus gros problème. Pour qu'un agent vocal fasse quelque chose d'utile, vous devez lui donner des instructions. Ce « prompt système » indique à l'IA qui elle est, quel est son rôle et comment agir. Tout ce bloc de texte est envoyé en tant que tokens d'entrée à chaque échange de la conversation. Un prompt détaillé peut facilement doubler ou tripler vos coûts, et vous pourriez ne même pas vous en rendre compte avant de recevoir la facture.
-
C'est un mélange d'audio et de texte. L'API jongle constamment entre les tokens audio (ce que dit l'utilisateur) et les tokens texte (ce que l'IA traite et répond), et chacun a son propre tarif. Ce mélange transforme une simple estimation des coûts en un jeu de devinettes.
Une analyse pratique du coût par minute
Pour dépasser la théorie, nous avons effectué quelques tests pour voir à quoi ressemblent réellement ces coûts de tokens en dollars par minute. Nous avons utilisé le Playground d'OpenAI pour simuler des conversations, car il fournit des données de coût en temps réel.
Nous avons comparé les modèles « gpt-4o-mini-realtime » et le plus costaud « gpt-4o-realtime ». Pour chacun, nous avons testé une conversation de base, puis une autre avec un prompt système de 1 000 mots, une configuration réaliste pour toute entreprise qui a besoin que son IA connaisse ses produits ou suive un script.
Les résultats ont été plutôt surprenants.
| Modèle et configuration | Coût moyen par minute | Pourquoi c'est important |
|---|---|---|
| GPT-4o mini (sans prompt système) | ~0,16 $ | Semble bon marché, mais une IA sans aucune instruction n'est pas utile pour une entreprise. |
| GPT-4o mini (avec un prompt système de 1 000 mots) | ~0,33 $ | Le coût a plus que doublé simplement en donnant à l'IA un manuel d'instructions de base. |
| GPT-4o (sans prompt système) | ~0,18 $ | Un peu plus cher, mais gère mieux les conversations complexes à plusieurs étapes. |
| GPT-4o (avec un prompt système de 1 000 mots) | ~1,63 $ | Le coût bondit de plus de 800 %. C'est exactement comme ça que les budgets sont anéantis. |
Le principal enseignement à tirer est que la tarification affichée pour GPT Realtime Mini n'est que le point de départ. Votre coût réel est presque entièrement déterminé par la manière dont vous configurez votre agent. Ce prompt système, dont vous avez absolument besoin pour tout cas d'utilisation professionnel, est le facteur qui fait le plus grimper votre facture. Cette volatilité rend difficile la budgétisation et la mise à l'échelle d'un projet d'IA vocale.
Au-delà des frais d'API : les autres coûts de création d'un agent IA vocal
La facture de l'API n'est qu'une partie de l'équation. Si vous prévoyez de créer un agent vocal à partir de zéro avec l'API Realtime, les coûts réels sont enfouis dans les heures d'ingénierie nécessaires pour le préparer pour les clients.
Comment l'ingénierie des prompts affecte vos coûts
Faire en sorte qu'une IA suive des instructions de manière fiable est plus difficile qu'il n'y paraît. Rédiger un bon prompt système demande beaucoup d'essais et d'erreurs. Un prompt bâclé conduit à une IA confuse, ce qui entraîne des clients frustrés et de l'argent jeté par les fenêtres.
Et il n'y a pas que le prompt. Vous devez fournir à l'IA les bonnes informations. Cela signifie construire un système pour la connecter à vos articles du centre d'aide, à vos wikis internes et à vos documents produits. C'est un gros travail d'ingénierie qui nécessite la mise en place de pipelines de données et de systèmes de récupération.
C'est là qu'un outil comme eesel AI s'avère utile. Il vous offre un éditeur de prompts simple et se connecte automatiquement à vos sources de connaissances. Vous pouvez lier votre Zendesk, Confluence ou Google Docs en quelques clics, sans avoir à coder.

Coûts d'intégration
Un agent vocal qui ne peut rien faire n'est pas d'une grande aide. Pour être utile, il doit se connecter à vos autres systèmes d'entreprise. Il doit pouvoir créer un ticket dans votre service d'assistance, vérifier le statut d'une commande dans Shopify ou transférer une conversation à un humain dans Slack.
Construire ces intégrations vous-même signifie du code personnalisé, la gestion des clés API et la gestion de l'authentification pour chaque outil. C'est une tonne de travail, et vous devez l'entretenir en permanence. En revanche, eesel AI dispose d'intégrations en un clic avec des dizaines d'outils professionnels courants, permettant à votre agent de passer à l'action dès le premier jour sans que vous ayez à écrire la moindre ligne de code.
Le risque d'un lancement sans tests appropriés : un coût caché
Comment savoir si votre agent est prêt pour le grand public avant de le laisser parler à de vrais clients ? Si vous le construisez vous-même, la réponse honnête est souvent : vous ne le savez pas.
Mettre en place un environnement de test approprié pour simuler des conversations réelles à grande échelle est un projet énorme en soi. Mais vous ne voulez vraiment pas lâcher une IA non testée sur votre clientèle. C'est un risque énorme pour votre réputation.
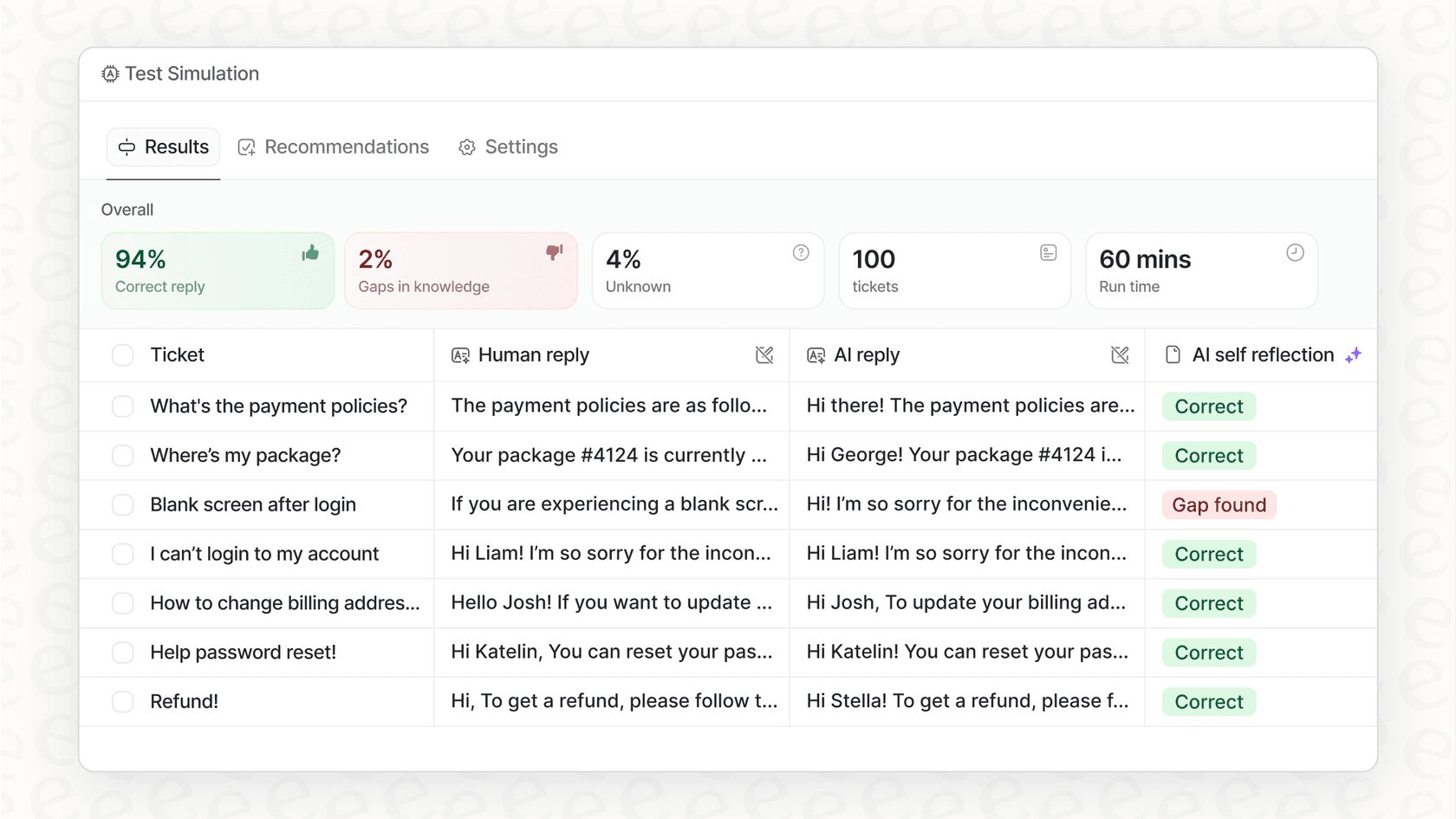
L'agent IA d'eesel AI aide à résoudre ce problème avec un mode de simulation. Vous pouvez tester votre agent sur des milliers de vos conversations d'assistance passées pour voir exactement comment il les aurait gérées. Cela vous donne une vision claire et basée sur les données de ses performances et de votre retour sur investissement potentiel, afin que vous puissiez vous lancer sans croiser les doigts.
Une alternative plus intelligente : des coûts prévisibles et un déploiement plus rapide
Au lieu de vous battre avec les tokens et de tout construire à partir de zéro, utiliser une plateforme d'IA tout-en-un est une bien meilleure solution pour la plupart des équipes. Ce n'est pas seulement moins cher à long terme, c'est aussi beaucoup plus rapide.
Soyez opérationnel en un après-midi
Un agent vocal personnalisé peut prendre des semaines, voire des mois, à une équipe d'ingénieurs pour être construit. Avec eesel AI, vous pouvez être opérationnel par vous-même en quelques heures. Toute la plateforme est conçue pour être en libre-service. Vous pouvez connecter vos connaissances, définir la personnalité et les règles de votre agent, et exécuter des simulations sans jamais avoir à planifier une démo.
Prenez le contrôle avec une tarification prévisible et transparente
Le plus grand problème avec l'utilisation directe de l'API est que vous ne savez jamais quel sera le montant de votre facture. Une semaine chargée pourrait entraîner une facture étonnamment élevée. eesel AI propose des forfaits transparents basés sur un nombre fixe d'interactions IA mensuelles. Vous savez exactement ce que vous payez chaque mois, donc il n'y a pas de mauvaises surprises.
De plus, vous bénéficiez d'un contrôle précis. Vous pouvez définir des règles qui déterminent exactement quelles questions l'IA gère et lesquelles sont directement envoyées à un humain. Cela vous permet de commencer petit en automatisant d'abord les tâches faciles et répétitives, puis d'évoluer en toute confiance, tout en maîtrisant vos coûts.

D'une tarification confuse à une valeur commerciale claire
Bien que la tarification brute de GPT Realtime Mini semble bon marché en surface, la réalité de la facturation basée sur les tokens est un véritable grand huit de coûts imprévisibles. De plus, les frais d'API ne représentent qu'une petite partie du coût réel de la création d'un agent vocal. Le véritable investissement réside dans la montagne de travail d'ingénierie nécessaire pour l'ajustement des prompts, les intégrations et les tests.
Une plateforme comme eesel AI offre une approche beaucoup plus saine. Elle utilise des modèles puissants comme GPT-4o mini mais gère toute la complexité pour vous. En offrant une plateforme en libre-service avec des intégrations en un clic, des tests puissants et une tarification prévisible, eesel AI vous offre un moyen plus rapide, plus sûr et plus abordable de lancer des agents IA qui aident réellement votre entreprise.
Prêt à voir à quel point cela peut être simple ? Arrêtez de vous soucier des tokens et commencez à automatiser. Essayez eesel AI gratuitement et mettez votre premier agent en ligne en quelques minutes.
Foire aux questions
Pourquoi la tarification de GPT realtime mini est-elle difficile à comprendre avec une facturation basée sur les tokens ?
La facturation basée sur les tokens rend la prévision des coûts difficile car des variables comme la durée des appels, les ratios entrée/sortie et l'inclusion constante de prompts système fluctuent de manière significative. Ces facteurs combinés rendent la prévision de vos dépenses un défi de taille.
À quel point un prompt système affecte-t-il la tarification de GPT realtime mini ?
Les prompts système peuvent augmenter considérablement les coûts car ils sont envoyés comme tokens d'entrée à chaque tour d'une conversation. Nos tests ont montré qu'un prompt détaillé de 1 000 mots peut plus que doubler le coût par minute par rapport à un agent sans instructions.
Quel est le coût moyen réaliste par minute pour la tarification de GPT realtime mini, en considérant une configuration d'entreprise standard ?
Notre analyse pratique a révélé qu'avec un prompt système nécessaire de 1 000 mots, le coût moyen pour GPT-4o mini peut être d'environ 0,33 $ par minute. Bien qu'un scénario sans prompt soit moins cher (environ 0,16 $), il ne représente pas une application commerciale utile.
Outre les frais directs de l'API, quels autres coûts cachés sont associés à la tarification de GPT realtime mini lors de la création d'un agent vocal ?
Au-delà des frais d'API, des coûts cachés importants incluent de nombreuses heures d'ingénierie pour l'ajustement des prompts, la création d'intégrations complexes avec les systèmes d'entreprise existants et le développement d'environnements de test appropriés. Ces efforts sont cruciaux mais souvent négligés dans les estimations de coûts initiales.
Existe-t-il une alternative à l'utilisation directe de l'API qui offre une tarification plus prévisible pour GPT realtime mini ?
Oui, des plateformes d'IA tout-en-un comme eesel AI proposent des plans de tarification transparents et prévisibles, généralement basés sur un nombre fixe d'interactions IA mensuelles. Cette approche élimine la volatilité de la facturation basée sur les tokens, permettant une meilleure gestion du budget et évitant les factures surprises.





Comment l'utilisation d'une plateforme peut-elle aider à réduire le temps et les efforts associés à la gestion de la tarification et du déploiement de GPT realtime mini ?
Des plateformes comme eesel AI réduisent considérablement le temps et les efforts de déploiement grâce à une configuration en libre-service, des intégrations en un clic et des fonctionnalités de test intégrées. Cela permet aux équipes de mettre en ligne des agents en quelques heures plutôt qu'en semaines ou mois de développement personnalisé, simplifiant la gestion des coûts et les opérations.