
Prendre des décisions éclairées grâce aux données n'est plus un luxe ; c'est ainsi que les entreprises modernes gardent une longueur d'avance. Le moteur de tout cela est un entrepôt de données cloud, l'endroit unique où toutes vos données analytiques sont centralisées. Lorsque vous commencez à en chercher un, deux noms reviennent constamment : Amazon Redshift et Google BigQuery. Ce sont tous deux des poids lourds, mais ils ont été conçus avec des philosophies très différentes.
Essayer de choisir entre les deux peut sembler un peu intimidant. Le meilleur choix dépend vraiment des besoins de votre équipe, de votre budget et du niveau d'implication que vous souhaitez avoir. Ce guide va clarifier le débat BigQuery vs Redshift, en les comparant sur l'architecture, la performance, le prix et leur utilisation au quotidien, afin que vous puissiez déterminer lequel est le plus adapté pour vous.
Qu'est-ce qu'un entrepôt de données cloud ?
Imaginez un entrepôt de données comme la bibliothèque centrale de toutes les données de votre entreprise. Il rassemble des informations de partout - votre CRM, vos outils de vente, vos plateformes de support - et les organise dans un but précis : l'analyse.
Il n'y a pas si longtemps, les entreprises devaient héberger ces entrepôts sur leurs propres serveurs, quelque part dans un placard. C'était cher, peu pratique et un véritable cauchemar à faire évoluer. Le passage au cloud a changé la donne, offrant un moyen beaucoup moins cher et plus flexible de gérer des ensembles de données massifs.
Pour comprendre pourquoi c'est important, il est utile de connaître la différence entre les systèmes OLTP (Traitement transactionnel en ligne) et OLAP (Traitement analytique en ligne). Vos applications quotidiennes, comme un système de point de vente qui enregistre un achat, sont des systèmes OLTP. Ils sont conçus pour de nombreuses petites transactions rapides. Les entrepôts de données sont des systèmes OLAP. Ils sont conçus pour analyser d'énormes quantités de données afin de répondre à des questions vastes et complexes, comme : « Quelle campagne marketing a attiré nos clients les plus précieux l'année dernière ? »
Qu'est-ce que Google BigQuery ?
Google BigQuery est l'entrepôt de données entièrement géré et sans serveur (serverless) de Google Cloud. Le mot magique ici est serverless. Vous n'avez pas à provisionner, configurer ou gérer la moindre infrastructure. Absolument rien. Il vous suffit de charger vos données et de commencer à écrire des requêtes SQL. En coulisses, le moteur Dremel de Google détermine la puissance de calcul dont vous avez besoin, la met en place et exécute la tâche. Cela le rend incroyable pour une mise à l'échelle à la volée et pour exécuter d'énormes requêtes ponctuelles sans aucune préparation.
Qu'est-ce qu'Amazon Redshift ?
Amazon Redshift est l'entrepôt de données géant d'AWS, à l'échelle du pétaoctet. Contrairement à BigQuery, c'est un système basé sur des clusters, ce qui signifie que vous devez provisionner un « cluster » en choisissant le nombre et le type de serveurs (ou nœuds) dont vous avez besoin. Cette approche vous donne un contrôle considérable sur les performances et les coûts, ce qui en fait un choix solide pour des charges de travail prévisibles et axées sur le reporting. Il est également intégré dans l'immense écosystème AWS, ce qui est un atout majeur si votre entreprise y est déjà installée.
Comparaison de l'architecture et de la scalabilité
La plus grande différence entre ces deux services réside dans leur mode de construction. Leur architecture détermine la manière dont ils évoluent, comment vous les gérez et, en fin de compte, si vous les trouverez agréables à utiliser ou s'ils seront une source constante de maux de tête.
Le modèle serverless « ça fonctionne tout seul » de BigQuery
BigQuery a été conçu pour être simple. Il sépare complètement son stockage de sa puissance de calcul. Lorsque vous exécutez une requête, Google alloue simplement les ressources nécessaires (appelées « slots ») pour l'exécuter. Une fois terminée, ces ressources sont libérées.
-
L'avantage : La mise à l'échelle est sans effort, surtout si votre charge de travail est en dents de scie ou imprévisible. Vous n'avez pas à gérer d'infrastructure, à redimensionner des clusters ou à vous soucier des temps d'arrêt. Ça fonctionne tout seul.
-
L'inconvénient : Cette approche « mains libres » signifie que vous avez moins de contrôle direct. Pour des charges de travail très spécifiques et constantes, vous pourriez trouver que ses performances ne sont pas aussi prévisibles qu'un cluster que vous avez réglé vous-même.
Le modèle de cluster « vous avez le contrôle » de Redshift
Redshift utilise un cluster provisionné plus traditionnel. Vous décidez du nombre de nœuds dont vous avez besoin et de leur type. Même avec les versions plus récentes comme les nœuds RA3 qui séparent le stockage et le calcul, vous gérez toujours la partie calcul comme un cluster distinct que vous faites évoluer vous-même, à la hausse ou à la baisse.
-
L'avantage : Vous obtenez un contrôle très précis sur les performances et les coûts. C'est parfait pour le reporting BI stable où vous avez besoin que les mêmes requêtes s'exécutent à la même vitesse, chaque jour.
-
L'inconvénient : Ce contrôle s'accompagne de plus de responsabilités. Vous êtes responsable de la mise à l'échelle manuelle ainsi que de la mise en pause et de la reprise des clusters pour économiser de l'argent. Cela ajoute une couche de gestion et nécessite une certaine expertise technique pour optimiser des éléments comme les clés de distribution et exécuter des tâches de maintenance pour que tout fonctionne parfaitement.
Bien que ce niveau de contrôle soit formidable pour certains, la tendance générale dans le logiciel est aux outils plus simples qui ne nécessitent pas une équipe d'ingénieurs pour fonctionner. Par exemple, des plateformes comme eesel AI permettent aux équipes de support de construire et de lancer des agents IA en quelques minutes sans toucher à une seule ligne de code, une tâche qui prenait autrefois des semaines de temps de développement.
Performances et cas d'usage courants
Ces différences architecturales ont un impact majeur sur la manière dont chaque plateforme se comporte. Il n'y en a pas une qui soit universellement « plus rapide » ; cela dépend vraiment de ce que vous faites.
Quand BigQuery brille pour l'exploration d'immenses jeux de données
BigQuery est conçu pour mobiliser une tonne de ressources parallèles pour une seule requête. Cela le rend incroyablement rapide pour l'analyse exploratoire et ad hoc sur des quantités massives de données. Si votre équipe de données pose constamment des questions nouvelles et complexes qui nécessitent d'analyser des tables gigantesques, BigQuery vous semblera probablement aussi rapide qu'une fusée.
- Parfait pour : L'exploration de données (data mining), la préparation de données pour les modèles d'apprentissage automatique, et l'exécution de ces requêtes occasionnelles mais très lourdes. C'est un favori des data scientists qui veulent juste explorer les données sans se soucier de la plomberie.
Où Redshift excelle avec le BI et les tableaux de bord cohérents
La force de Redshift est sa constance. Comme vous avez réservé un ensemble de ressources dédiées, il est conçu pour fournir des performances fiables et rapides pour les mêmes requêtes, encore et encore. Vous pouvez également l'affiner avec des éléments comme les clés de tri (sort keys) pour rendre ces requêtes répétitives encore plus rapides.
- Parfait pour : Alimenter des tableaux de bord BI dans des outils comme Tableau ou Amazon QuickSight, générer des rapports financiers quotidiens, et gérer de nombreux utilisateurs simultanés où une vitesse prévisible est essentielle. C'est souvent le premier choix pour les équipes de business intelligence en entreprise.
Gestion et facilité d'utilisation
Au-delà de la vitesse pure, il est utile de réfléchir à ce que cela implique de vivre avec chaque plateforme au quotidien.
La simplicité de BigQuery
BigQuery est conçu pour ne nécessiter pratiquement aucune administration de base de données. Il n'y a pas d'index à créer, pas de commandes de nettoyage à exécuter et pas de clusters à configurer. Vous pouvez charger des données et exécuter des requêtes en quelques minutes. Il gère également nativement les données imbriquées comme le JSON, que vous devez souvent aplatir avant de les charger dans Redshift.
L'approche pratique de Redshift
Redshift vous met aux commandes, ce qui signifie aussi que vous êtes le mécanicien. Vous devrez choisir les types de nœuds, configurer les clés de distribution et de tri pour optimiser les requêtes, et exécuter des tâches de maintenance de temps en temps. Cela donne aux utilisateurs avancés de nombreux leviers à actionner, mais cela signifie également une courbe d'apprentissage plus abrupte et nécessite souvent quelqu'un avec des compétences de DBA (administrateur de bases de données) dans l'équipe.
BigQuery est une bonne option si vous n'avez pas l'expertise ou les ressources DBA pour gérer un cluster. Redshift est fait pour vous si vous avez besoin de plus de contrôle/réglages pour une charge de travail prévisible et que vous disposez des ressources nécessaires.
Une analyse détaillée de la tarification BigQuery vs Redshift
Parlons argent. La tarification est un facteur énorme, et les deux plateformes ont des modèles qui peuvent être soit très bon marché, soit étonnamment chers, tout dépend de la façon dont vous les utilisez.
Le modèle de paiement à l'utilisation de BigQuery
BigQuery divise sa tarification en deux catégories : le calcul (l'exécution des requêtes) et le stockage.
-
Tarification du calcul (Analyse) :
- À la demande : Vous payez pour la quantité de données que vos requêtes analysent. Le tarif standard est de 6,25 $ par téraoctet (Tio), et vous bénéficiez de votre premier Tio gratuit chaque mois. C'est idéal lorsque vous débutez ou avez des besoins imprévisibles.
- Capacité (Éditions) : Pour des coûts plus prévisibles, vous pouvez réserver une quantité définie de puissance de traitement (mesurée en « slot-heures »). Cela commence à 0,04 $ par slot-heure et est judicieux pour des charges de travail constantes et à volume élevé.
-
Tarification du stockage :
- Stockage actif : Vous paierez environ 0,02 $ par Go par mois pour les données dans les tables qui ont été modifiées au cours des 90 derniers jours.
- Stockage à long terme : Si une table n'a pas été touchée pendant 90 jours, le prix baisse automatiquement à environ 0,01 $ par Go par mois.
N'oubliez pas que l'ingestion de données en streaming dans BigQuery ou l'utilisation d'autres services connexes peuvent avoir leurs propres coûts.
Le modèle de tarification provisionnée de Redshift
Avec Redshift, vous payez principalement pour le cluster de calcul que vous avez configuré.
-
Tarification du calcul (Nœud) :
- À la demande : Vous payez un tarif horaire basé sur le type et le nombre de nœuds de votre cluster. Un nœud populaire de type « ra3.xlplus », par exemple, coûte 1,086 $ par heure. Un avantage énorme est que vous pouvez mettre en pause votre cluster lorsque vous ne l'utilisez pas pour économiser de l'argent.
- Instances réservées : Si votre charge de travail est stable, vous pouvez vous engager pour une durée de 1 ou 3 ans pour obtenir d'énormes réductions, parfois jusqu'à 75 % sur le tarif à la demande.
-
Tarification du stockage géré (pour les nœuds RA3) :
- Ceci est facturé séparément de vos nœuds de calcul à environ 0,024 $ par Go par mois.
-
Option Serverless : Pour mieux concurrencer la simplicité de BigQuery, Redshift propose désormais une option serverless. Elle est facturée en « Unités de Traitement Redshift » (RPU) par heure, à partir de 0,36 $ par RPU-heure.
| Caractéristique | Google BigQuery | Amazon Redshift |
|---|---|---|
| Modèle principal | Paiement par requête (calcul) + stockage | Paiement à l'heure (cluster provisionné) + stockage |
| Calcul à la demande | 6,25 $ par Tio analysé | À partir d'environ 0,543 $/heure par nœud |
| Calcul à tarif forfaitaire | Oui (Éditions, par slot-heure) | Oui (Instances réservées, engagement de 1 à 3 ans) |
| Coût du stockage | ~0,02 $/Go/mois (actif) | ~0,024 $/Go/mois (stockage géré) |
| Idéal pour | Charges de travail imprévisibles et en dents de scie | Charges de travail cohérentes et prévisibles |
BigQuery vs Redshift : Quel entrepôt de données est fait pour vous ?
Alors, après tout cela, lequel devriez-vous choisir ? La décision BigQuery vs Redshift se résume vraiment à un compromis : préférez-vous la simplicité ou le contrôle ?
-
Choisissez BigQuery si : Vous voulez passer moins de temps à gérer l'infrastructure et plus de temps à analyser les données. C'est parfait si vos schémas de requêtes sont très variables, si votre équipe vit dans l'écosystème Google Cloud, ou si vous avez des data scientists qui ont besoin d'exécuter des requêtes exploratoires massives sans avoir à ouvrir un ticket auprès d'un DBA.
-
Choisissez Redshift si : Vous avez besoin de performances solides et prévisibles pour vos tableaux de bord et rapports BI. C'est le meilleur choix si vos charges de travail sont stables, si vous voulez un contrôle précis sur les ressources pour gérer les coûts, et si vous êtes déjà fortement investi dans l'écosystème AWS.
En fin de compte, il n'y a pas d'entrepôt de données unique qui soit le « meilleur ». Le bon choix est celui qui correspond aux compétences de votre équipe, au budget de votre entreprise et à vos objectifs réels.
Au-delà de l'analytique : Connecter les connaissances de votre équipe
Alors que BigQuery et Redshift sont incroyables pour gérer vos données structurées, une grande partie de la véritable connaissance de votre entreprise - anciens tickets de support, wikis internes, documents de projet - est éparpillée partout dans des formats non structurés. C'est là qu'une plateforme de connaissance IA peut faire une énorme différence.
eesel AI se connecte à toutes les applications et sources de connaissances de votre entreprise, des services d'assistance comme Zendesk et Freshdesk aux wikis comme Confluence et Google Docs. Elle rassemble toutes ces connaissances dispersées pour alimenter des agents IA capables d'automatiser le support client, d'aider vos agents humains à rédiger de meilleures réponses, et de fournir des réponses instantanées et précises à vos équipes internes directement dans Slack ou Microsoft Teams.
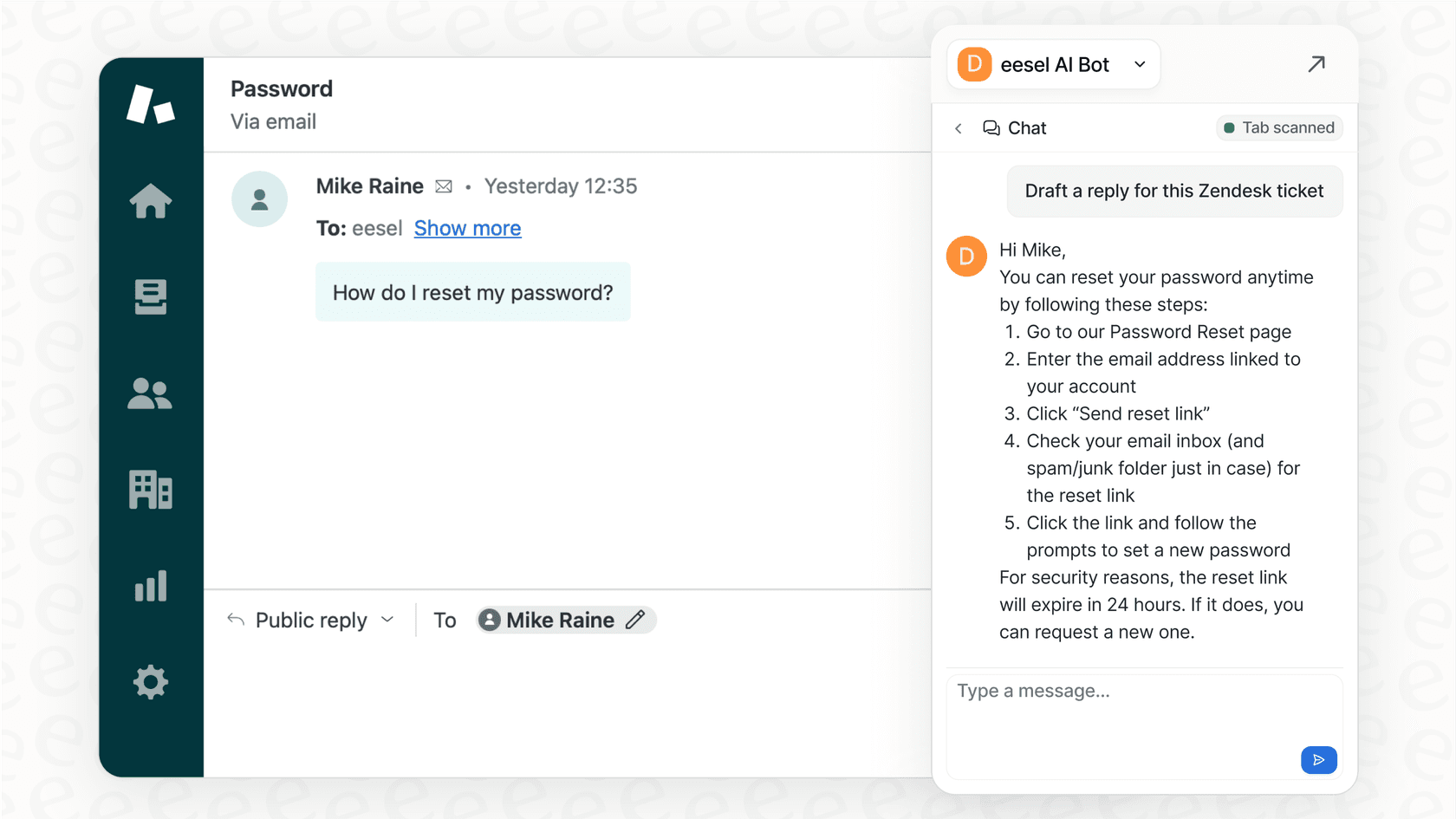
Si vous cherchez à transformer l'intelligence collective de votre équipe en un moteur de support automatisé qui fonctionne vraiment, essayez eesel AI gratuitement.
Foire aux questions
Le modèle serverless et de paiement à l'utilisation de BigQuery est généralement plus indulgent pour les volumes de données inconnus et les schémas de requêtes imprévisibles. Vous ne payez que ce que vous utilisez, sans avoir besoin de pré-provisionner une infrastructure ou de vous soucier d'un sur-provisionnement.
La tarification à la demande de BigQuery, basée sur les données analysées, est mieux adaptée à une utilisation irrégulière car vous ne payez que lorsque des requêtes sont exécutées. Le modèle provisionné traditionnel de Redshift, facturé à l'heure, peut être plus coûteux pendant les périodes d'inactivité, à moins de mettre manuellement le cluster en pause ou d'utiliser son option serverless.
Redshift excelle dans le reporting BI constant grâce à son modèle de cluster provisionné, qui offre des performances prévisibles pour les requêtes répétitives. Son contrôle précis permet une optimisation (comme les clés de tri) adaptée aux besoins stables des tableaux de bord quotidiens.
BigQuery est conçu pour une administration minimale, ne nécessitant presque aucune compétence de DBA pour la configuration ou la maintenance. Redshift, étant un système basé sur des clusters, requiert une gestion plus pratique, incluant le choix des types de nœuds et l'optimisation des performances, ce qui bénéficie souvent de l'expertise d'un DBA.
BigQuery offre une mise à l'échelle sans effort grâce à son architecture serverless, allouant automatiquement les ressources selon les besoins. Redshift nécessite une mise à l'échelle manuelle de ses clusters, bien que ses nœuds RA3 et son option serverless offrent plus de flexibilité que les anciennes versions.
Si votre entreprise est déjà bien ancrée dans l'écosystème AWS, Redshift offre une intégration transparente avec d'autres services AWS comme S3, EC2 et QuickSight. Bien que BigQuery puisse se connecter aux données AWS, une intégration native au sein de votre environnement cloud existant simplifie souvent les opérations.
BigQuery est particulièrement bien adapté à l'analyse exploratoire sur des jeux de données massifs, surtout s'ils contiennent des structures imbriquées comme du JSON. Son architecture lui permet de mobiliser d'importantes ressources parallèles sur des requêtes complexes et ad hoc, ce qui en fait un favori des data scientists.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.








