Le « cerveau » de tout agent de support IA est sa base de connaissances. La manière dont vous alimentez ce cerveau en informations, un processus appelé ingestion de connaissances, est sans doute l'étape la plus importante pour obtenir des réponses précises, utiles et humaines. Si vous réussissez, votre IA devient une star. Si vous échouez, vous venez de créer un chatbot très cher et très frustrant.
Ada est un grand nom dans le domaine du service client par IA, surtout auprès des grandes entreprises. Alors, comment gèrent-ils cette première étape cruciale ?
Ce guide vous donnera un aperçu clair et direct du processus d'ingestion de connaissances d'Ada. Nous allons détailler son fonctionnement, ses points forts et certaines limites potentielles que vous devriez connaître avant de vous lancer.
Qu'est-ce qu'Ada ?
Ada est une plateforme alimentée par l'IA conçue pour automatiser les conversations de support client. Vous la verrez souvent utilisée par de grandes entreprises dans les secteurs de l'e-commerce, de la finance et de la technologie. Son rôle principal est d'aider les entreprises à créer et à utiliser des agents d'IA conversationnels (ou chatbots) capables de discuter avec les clients sur différents canaux et, espérons-le, de résoudre leurs problèmes sans intervention humaine.
Comprendre l'ingestion de connaissances pour les agents IA
Alors, qu'est-ce que l'« ingestion de connaissances » exactement ? Considérez simplement cela comme le processus de collecte de toutes les informations de votre entreprise, de leur traitement et de leur organisation pour qu'un agent IA puisse réellement les utiliser pour répondre aux questions.
C'est comme donner à un nouvel employé un examen à livre ouvert. Mieux ses notes et ses ressources (la base de connaissances) sont organisées, meilleurs seront ses résultats. Le tout est alimenté par une technologie appelée Génération Augmentée par Récupération (RAG), une manière élégante de dire que l'IA peut consulter ses « notes » avant de formuler une réponse.
graph TD A[Début : Le client pose une question] --> B{L'agent IA reçoit la requête} ; B --> C[Étape 1 : Connexion des sources L'IA accède aux bases de connaissances connectées comme les centres d'aide, les documents, les sites web] ; C --> D[Étape 2 : Traitement du contenu L'IA décompose les grands documents en fragments plus petits et gérables] ; D --> E[Étape 3 : Indexation L'IA utilise une carte de recherche pour trouver les fragments d'informations les plus pertinents] ; E --> F[L'IA génère une réponse] ; F --> G[Le client reçoit la réponse] ;
style A fill:#f9f,stroke:#333,stroke-width:2px style G fill:#f9f,stroke:#333,stroke-width:2px
Cela se résume généralement à trois parties principales :
-
Connexion des sources : C'est là que vous indiquez à l'IA où se trouvent vos informations, que ce soit un centre d'aide, un dossier de documents ou un site web.
-
Traitement du contenu : L'IA prend tous ces grands documents et les décompose en morceaux plus petits et plus faciles à gérer pour qu'elle puisse les comprendre.
-
Indexation : Enfin, elle crée une « carte » consultable de toutes ces informations. Lorsqu'une question arrive, elle peut utiliser cette carte pour trouver la bonne réponse en un clin d'œil.
La simplicité et la flexibilité de ce processus ont un impact énorme sur la rapidité avec laquelle vous pouvez mettre en place un agent IA réellement utile.
Comment fonctionne l'ingestion de connaissances d'Ada
Ada a plusieurs manières spécifiques d'intégrer les connaissances, principalement axées sur le contenu structuré qui se trouve déjà dans un service d'assistance. Examinons leurs méthodes.
Connexion à des intégrations de bases de connaissances pré-construites
La principale méthode d'Ada pour acquérir des connaissances est de se connecter à des plateformes de service d'assistance établies où vous avez probablement déjà une base de connaissances. Leur documentation mentionne plusieurs intégrations pré-construites, notamment Zendesk, Salesforce, Contentful, Dixa et Gladly.
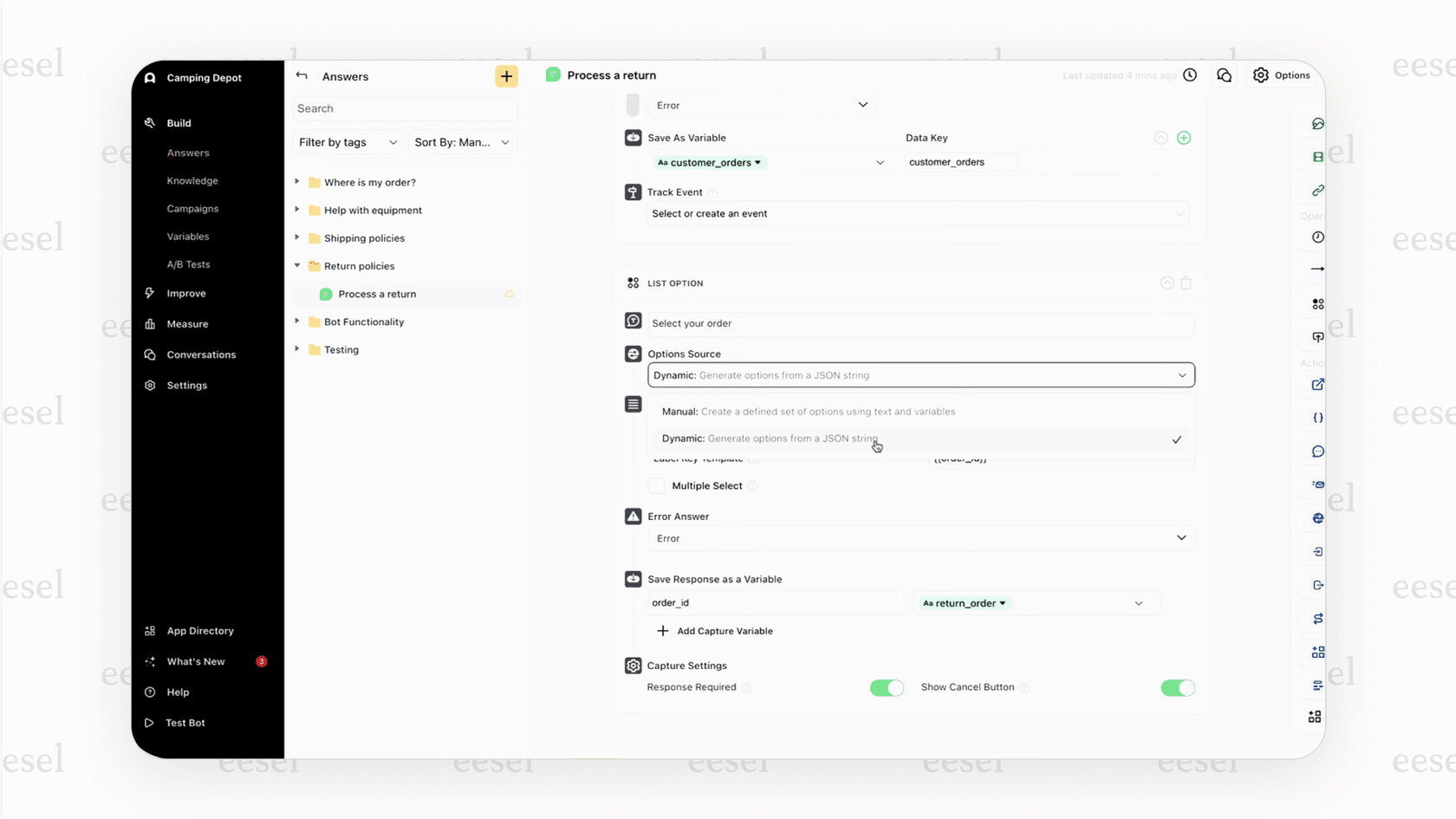
La configuration implique généralement de se connecter au tableau de bord d'Ada, de choisir votre outil et de saisir vos identifiants, comme une clé API ou un sous-domaine. Ensuite, vous ajustez quelques paramètres, et Ada commence à importer vos articles.
Mais il y a quelques bémols. Selon leur propre documentation, ce processus nécessite souvent que votre base de connaissances soit publique (non protégée par un identifiant). Cela peut aussi dépendre du fait que votre centre d'aide utilise la structure d'URL par défaut de la plateforme. Si votre entreprise a une configuration personnalisée, vous pourriez vous heurter à un mur ici.
Utiliser l'API Knowledge pour des sources personnalisées
Et si vos connaissances ne se trouvent pas dans Zendesk ou Salesforce ? Pour pratiquement toute autre source de données, Ada vous demande d'utiliser leur API Knowledge.
Une API est excellente pour la flexibilité, mais c'est une solution avant tout destinée aux développeurs. Cela signifie que vous aurez besoin d'un ingénieur dans votre équipe pour écrire du code afin de construire, et surtout, de maintenir une connexion personnalisée. Si vous voulez connecter quelque chose d'aussi simple qu'une collection de Google Docs, vous vous retrouvez soudainement avec un mini-projet d'ingénierie.
C'est là que la plateforme commence à paraître un peu dépassée. Les outils plus récents proposent des intégrations en libre-service et sans code pour une bien plus grande variété de sources. Par exemple, une plateforme comme eesel AI permet à n'importe qui dans votre équipe de connecter des connaissances provenant de sources comme Google Docs ou Confluence en quelques clics, sans diplôme d'ingénieur requis.
Synchronisation des données et exigences de contenu
Une fois que vous êtes connecté, le système d'Ada se synchronise de temps en temps avec vos bases de connaissances. Pour Zendesk et Salesforce, c'est environ toutes les 15 minutes. Pour d'autres comme Dixa ou Gladly, cela peut aller jusqu'à toutes les six heures. Cela signifie que votre IA pourrait ne pas avoir les informations les plus récentes si vous venez de publier une mise à jour critique.
Ada suggère également d'utiliser un contenu propre et logiquement structuré. Bien que ce soit un bon conseil pour n'importe quelle IA, cela suggère que vous pourriez devoir passer beaucoup de temps à réécrire et préparer vos documents existants avant qu'ils ne puissent être utilisés efficacement. C'est une autre étape manuelle ajoutée à la liste.
Principales limites du modèle d'ingestion d'Ada
Bien que l'approche d'Ada fonctionne, elle présente des limites importantes qui peuvent affecter la qualité de votre support IA et la rapidité avec laquelle vous pouvez le lancer.
Prise en charge limitée des connaissances non structurées
Le modèle d'Ada s'appuie fortement sur des articles de base de connaissances parfaitement structurés et pré-rédigés. Mais réfléchissez-y : où se trouve réellement votre connaissance de support la plus précieuse ? Elle est probablement enfouie dans d'anciens tickets de support, dans les milliers de conversations réelles où vos meilleurs agents ont déjà résolu les problèmes les plus difficiles de vos clients.
Le processus d'ingestion d'Ada n'a pas de moyen intégré d'apprendre de cette mine d'or d'informations désordonnées et non structurées. Tout ce contexte précieux, la voix unique de votre marque et les solutions éprouvées de votre équipe sont laissés de côté. Votre IA part d'une base théorique, et non d'une pratique réelle.
C'est une énorme occasion manquée. Une plateforme plus moderne comme eesel AI peut s'entraîner directement sur vos tickets de service d'assistance historiques dès le premier jour. Elle adopte automatiquement le ton de votre marque, comprend les détails subtils des vrais problèmes des clients et trouve des solutions qui ont déjà fonctionné. C'est la différence entre une IA qui lit simplement un manuel et une qui sonne comme votre meilleur agent.
Un processus de configuration manuel et rigide
Connecter chaque source dans Ada implique une configuration spécifique en plusieurs étapes qui peut être un peu capricieuse. Si vous utilisez un outil qui ne figure pas sur leur courte liste d'intégrations, vous êtes immédiatement renvoyé vers un projet de développement avec leur API.
Cela crée un système rigide où vous devez adapter vos outils et vos flux de travail à la plateforme, plutôt que l'inverse. Cela ralentit les choses et crée une dépendance vis-à-vis du personnel technique que de nombreuses équipes de support n'ont tout simplement pas à disposition.
En revanche, eesel AI offre une expérience ultra-simple et en libre-service. Vous pouvez connecter votre service d'assistance et d'autres sources de connaissances avec des intégrations en un clic et être opérationnel en quelques minutes, pas en quelques mois. L'idée est de s'intégrer à votre flux de travail existant sans causer de maux de tête majeurs.
Absence de tests sans risque
Après avoir pris toute la peine de configurer votre ingestion de connaissances, la grande question est : « Comment cette IA se comportera-t-elle réellement face aux questions réelles des clients ? »
La documentation d'Ada ne mentionne pas d'outil de simulation qui vous permet de tester les performances de l'IA sur vos anciens tickets avant de la laisser parler aux clients. Cela signifie que vous devez vous lancer avec beaucoup d'incertitude, en gros, en appuyant sur un interrupteur et en espérant que tout se passe bien. Vous testez en production, ce qui est un jeu risqué lorsque la satisfaction client est en jeu.
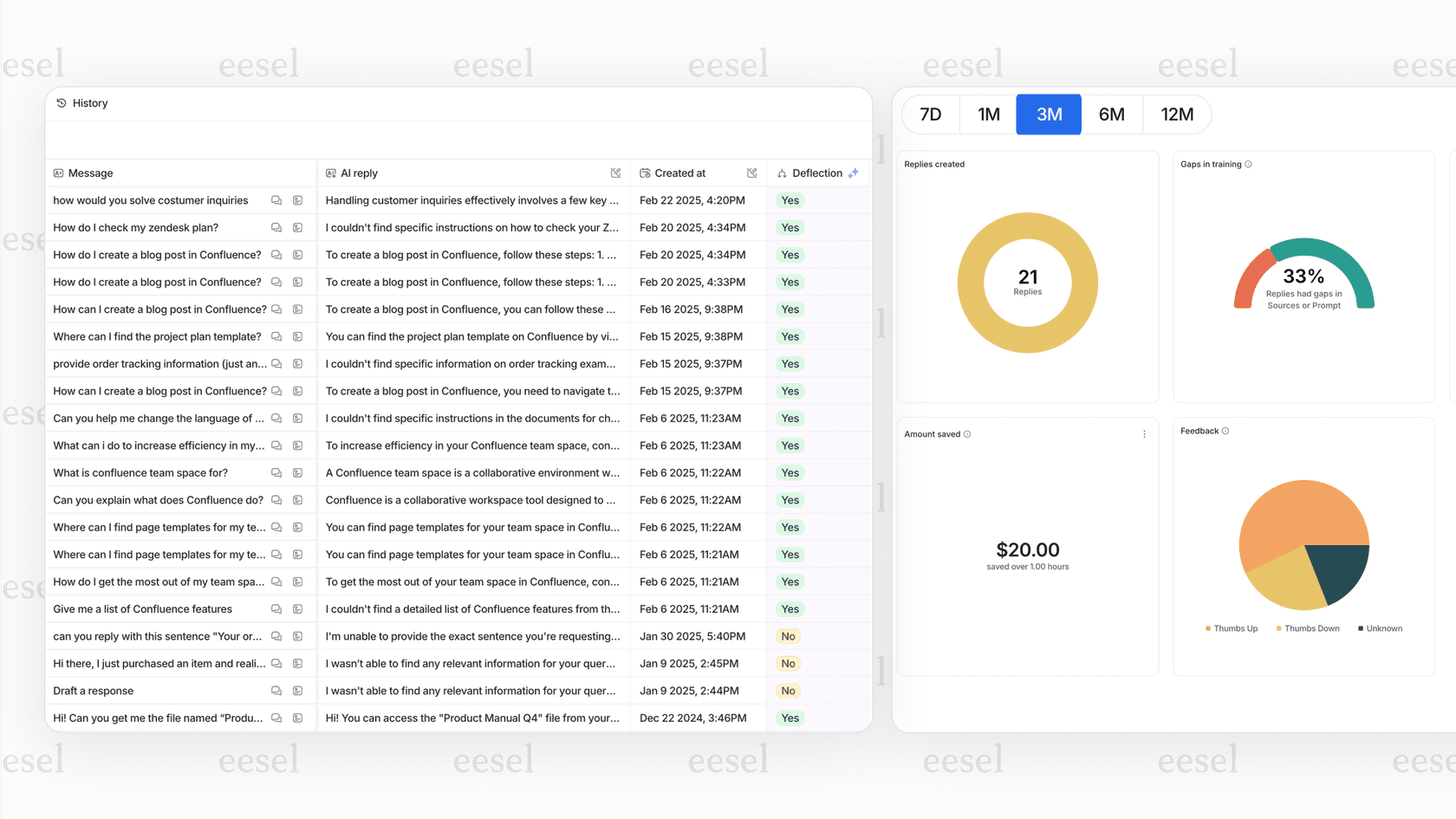
C'est un autre domaine où les plateformes plus récentes ont pris de l'avance. Par exemple, le mode simulation d'eesel AI vous permet de tester en toute sécurité votre IA sur des milliers de tickets passés dans un environnement privé. Il vous donne une prévision solide de son taux de résolution, vous montre exactement comment il répondra à différentes questions et vous aide à repérer les lacunes dans les connaissances. Vous pouvez acquérir une confiance totale et ajuster son comportement avant qu'un seul client n'interagisse avec lui.
Tarifs
Les tarifs d'Ada ne sont pas affichés sur leur site web. C'est assez courant pour les logiciels d'entreprise, mais cela signifie que vous devez contacter leur équipe commerciale pour obtenir un devis.
Le principal inconvénient ici est que vous pourriez passer par un long processus de vente juste pour savoir si cela correspond à votre budget. Les coûts peuvent également être difficiles à prévoir, car ils peuvent être liés à des éléments comme le volume de tickets ou le nombre de résolutions, qui peuvent changer d'un mois à l'autre.
Pour les équipes qui préfèrent un peu plus de transparence, d'autres plateformes ont des tarifs clairs et prévisibles. Par exemple, les forfaits d'eesel AI sont publics et faciles à comprendre.
| Forfait | Prix mensuel (facturé mensuellement) | Fonctionnalités clés |
|---|---|---|
| Team | 299 $ | Entraînement sur sites web/documents, intégration Slack, Copilote IA |
| Business | 799 $ | Tout ce qui est dans Team + entraînement sur les tickets passés, Actions IA personnalisées, simulation en masse |
| Custom | Contacter le service commercial | Intégrations avancées, orchestration multi-agents, contrôles personnalisés |
Un détail clé ici est que les tarifs d'eesel AI sont basés sur un nombre défini d'interactions IA chaque mois, sans frais supplémentaires par résolution. Votre facture n'augmentera pas soudainement simplement parce que vous avez eu un mois chargé en support. De plus, avec des forfaits mensuels flexibles, vous pouvez commencer petit et annuler à tout moment sans être enfermé dans un contrat à long terme.
Une meilleure alternative : l'ingestion de connaissances flexible avec eesel AI
Bien qu'Ada soit une plateforme solide, son modèle d'ingestion de connaissances peut sembler un peu rigide, lourd pour les développeurs, et il n'offre pas de moyen sûr de tester avant le lancement. Pour les équipes qui ont besoin d'aller vite et de rester flexibles, il existe une meilleure solution.
eesel AI est l'alternative moderne, conçue pour la vitesse, la flexibilité et la confiance. Elle vous offre une manière beaucoup plus intuitive et puissante de construire le cerveau de votre IA.
Title: Ingestion de connaissances : Ada vs eesel AI Ada Side:
-
Icône pour sources limitées (Services d'assistance comme Zendesk, Salesforce).
-
Icône pour API, légendée « Nécessite des développeurs pour les sources personnalisées. »
-
Icône pour synchronisation lente, légendée « Synchronisation toutes les 15 min à 6 heures. »
-
Icône pour absence de test, légendée « Pas de mode de simulation sans risque. » eesel AI Side:
-
Icônes pour sources multiples (Services d'assistance, Confluence, Google Docs, etc.), légendées « Des dizaines d'intégrations sans code. »
-
Icône pour libre-service, légendée « N'importe qui peut connecter des sources en quelques minutes. »
-
Icône pour synchronisation en temps réel, légendée « Apprend à partir des données en temps réel. »
-
Icône pour simulation, légendée « Testez en toute sécurité sur les tickets passés avant le lancement. »
Voici un bref résumé de la différence :
-
Connectez tout sans prise de tête : Branchez instantanément des centres d'aide, des tickets passés, Confluence, Google Docs, et des dizaines d'autres sources, sans avoir besoin de code.
-
Soyez opérationnel en quelques minutes, pas en quelques mois : C'est une plateforme véritablement en libre-service. Vous pouvez vous inscrire, connecter vos outils et avoir un agent IA fonctionnel prêt à l'emploi en quelques minutes, sans jamais parler à un commercial.
-
Apprenez du meilleur travail de votre équipe : L'IA analyse automatiquement les résolutions de tickets passés, de sorte que ses réponses sont basées sur ce qui a réellement fonctionné pour vos clients.
-
Testez en toute confiance : Utilisez le mode simulation pour voir ses performances et obtenir une prévision claire de votre retour sur investissement avant de l'activer pour les clients.
Bien réussir l'ingestion de connaissances
Bien réussir l'ingestion de connaissances est le fondement de toute bonne stratégie de support par IA. Elle doit être assez simple pour que n'importe qui dans l'équipe puisse la gérer, assez puissante pour intégrer toutes vos connaissances, et assez flexible pour évoluer avec vous.
Alors que les plateformes traditionnelles comme Ada offrent une approche structurée mais souvent rigide, des solutions modernes comme eesel AI apportent la vitesse, la flexibilité et l'apprentissage intelligent dont les équipes de support d'aujourd'hui ont vraiment besoin. En automatisant les tâches lourdes et en vous donnant les outils pour vous lancer en toute confiance, vous pouvez cesser de passer des mois en configuration et commencer à voir des résultats en quelques jours.
Prêt à voir à quoi ressemble un processus d'ingestion de connaissances vraiment fluide ? Essayez eesel AI.
Foire aux questions
Si vos connaissances ne se trouvent pas dans une plateforme pré-intégrée, Ada vous demande d'utiliser son API Knowledge. Cela signifie que votre équipe aura besoin d'un ingénieur pour écrire et maintenir du code personnalisé afin de créer des connexions, ce qui peut transformer une tâche simple en un projet de développement.
Oui, l'ingestion de connaissances d'Ada repose fortement sur des articles de base de connaissances parfaitement structurés et pré-rédigés. Elle ne dispose pas d'un moyen intégré pour apprendre à partir de sources de données non structurées, telles que les tickets de support historiques, qui contiennent souvent des solutions précieuses du monde réel.
L'ingestion de connaissances d'Ada synchronise les données des bases de connaissances connectées à des intervalles variables. Pour des plateformes comme Zendesk et Salesforce, c'est environ toutes les 15 minutes, tandis que pour d'autres comme Dixa ou Gladly, cela peut prendre jusqu'à six heures. Cela signifie que votre IA pourrait ne pas toujours disposer des informations les plus récentes immédiatement après une mise à jour.
La documentation d'Ada ne mentionne pas d'outil de simulation intégré pour tester les performances de l'IA sur les tickets passés avant le déploiement. Cela signifie que vous vous lancez généralement avec une certaine incertitude, en testant essentiellement dans un environnement de production en direct avec de vrais clients.
La configuration de l'ingestion de connaissances d'Ada est souvent un processus en plusieurs étapes, surtout si vous devez utiliser leur API pour des sources non standard, ce qui nécessite l'intervention d'un développeur. Cela peut rendre le processus rigide, obligeant vos flux de travail à s'adapter à la structure d'Ada plutôt que l'inverse.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.



L'ingestion de connaissances d'Ada se connecte principalement via des intégrations pré-construites avec des plateformes de service d'assistance populaires comme Zendesk, Salesforce et Contentful. Vous vous connectez généralement au tableau de bord d'Ada, sélectionnez votre plateforme et saisissez vos identifiants. Ce processus permet ensuite à Ada d'importer les articles de votre base de connaissances existante.