Hay mucho revuelo en torno a la API en tiempo real de OpenAI y, sinceramente, tiene sentido. La idea de crear agentes de voz similares a los humanos y superresponsivos es bastante emocionante. El modelo que más llama la atención es el «gpt-4o-mini-realtime», principalmente porque promete un rendimiento sólido a un precio que parece irrisorio.
Pero aquí está el detalle. En cuanto consultas la página de precios, te topas con jerga como «por millón de tokens» para texto, audio y algo llamado entradas en caché. Esto nos deja a la mayoría rascándonos la cabeza y haciéndonos la misma pregunta: «Vale, pero ¿cuánto me cuesta eso realmente por minuto?»
Si estás tratando de averiguar si un proyecto es viable o simplemente intentando establecer un presupuesto, los precios basados en tokens son un verdadero engorro. Por eso, hemos decidido hacer los cálculos por ti. Esta guía desglosa el coste real de usar GPT realtime mini, revelando los factores ocultos que pueden hacer que tus gastos se disparen cuando menos te lo esperas.
Entendiendo la API en tiempo real de OpenAI
Antes de meternos en los números, pongámonos de acuerdo. La API en tiempo real de OpenAI es una herramienta para desarrolladores que quieren crear aplicaciones con conversaciones de voz a voz rápidas. Básicamente, te permite crear una IA que puede escuchar y responder casi al instante, sin el incómodo retardo que se produce con la tecnología más antigua.
Está diseñada para potenciar los agentes de voz. Piensa en una IA que puede gestionar llamadas de atención al cliente, reservar citas o responder preguntas internas para tu equipo, todo ello con un sonido natural.
La API te ofrece un par de modelos con los que trabajar. Está el potente «gpt-4o-realtime» para conversaciones más complicadas, y su hermano más barato y rápido, «gpt-4o-mini-realtime». Nos vamos a centrar en la versión mini porque su bajo precio de etiqueta la convierte en el punto de partida para muchos.
El problema de los precios basados en tokens de OpenAI
OpenAI te cobra por cada «token» que utiliza tu aplicación. Un token es solo una pequeña pieza de datos, podría ser una palabra, una sílaba o un fragmento de audio. El coste se basa en cuántos tokens envías al modelo (entrada) y cuántos te devuelve (salida).
Aquí están los precios oficiales de GPT realtime mini de la página de precios de OpenAI:
| Modelo y tipo de token | Precio de entrada (por millón de tokens) | Precio de salida (por millón de tokens) |
|---|---|---|
| gpt-4o-mini-realtime-preview | ||
| Texto | 0,60 $ | 2,40 $ |
| Audio | 10,00 $ | 20,00 $ |
| Entrada de audio en caché | 0,30 $ | N/A |
Estas cifras parecen minúsculas, ¿verdad? Pero este modelo hace que sea increíblemente difícil prever tus costes por varias razones:
-
La duración de las llamadas es muy variable. Una charla rápida de un minuto utiliza muchos menos tokens que una llamada de soporte compleja de diez minutos. ¿Cómo puedes predecir la media?
-
La relación entrada-salida cambia. Un cliente hablador y una IA silenciosa costarán menos que un cliente silencioso que necesita explicaciones largas y detalladas de la IA.
-
Prompts de sistema: el coste oculto. Este es el más importante. Para hacer que un agente de voz haga algo útil, tienes que darle instrucciones. Este «prompt de sistema» le dice a la IA quién es, cuál es su trabajo y cómo debe actuar. Todo este bloque de texto se envía como tokens de entrada con cada intercambio de la conversación. Un prompt detallado puede duplicar o triplicar fácilmente tus costes, y puede que ni te des cuenta hasta que llegue la factura.
-
Es una mezcla de audio y texto. La API está constantemente haciendo malabares con tokens de audio (lo que dice el usuario) y tokens de texto (lo que la IA procesa y responde), y cada uno tiene su propia etiqueta de precio. Esta mezcla convierte la simple estimación de costes en un juego de adivinanzas.
Un desglose práctico del coste por minuto
Para superar la teoría, realizamos algunas pruebas para ver cómo se traducen estos costes de tokens en dólares por minuto. Usamos el OpenAI Playground para simular conversaciones, ya que proporciona datos de costes en tiempo real.
Comparamos tanto el modelo «gpt-4o-mini-realtime» como el más potente «gpt-4o-realtime». Para cada uno, probamos una conversación básica y luego otra con un prompt de sistema de 1000 palabras, una configuración realista para cualquier empresa que necesite que su IA conozca los productos o siga un guion.
Los resultados fueron bastante sorprendentes.
| Modelo y configuración | Coste medio por minuto | Por qué es importante |
|---|---|---|
| GPT-4o mini (sin prompt de sistema) | ~0,16 $ | Parece barato, pero una IA sin ninguna instrucción no es útil para una empresa. |
| GPT-4o mini (con prompt de sistema de 1000 palabras) | ~0,33 $ | El coste se duplica con creces con solo darle a la IA un manual de instrucciones básico. |
| GPT-4o (sin prompt de sistema) | ~0,18 $ | Un poco más caro, pero gestiona mejor las conversaciones complejas y de varios pasos. |
| GPT-4o (con prompt de sistema de 1000 palabras) | ~1,63 $ | El coste se dispara más de un 800 %. Así es exactamente como se arruinan los presupuestos. |
La principal conclusión es que el precio anunciado de GPT realtime mini es solo el punto de partida. Tu coste real depende casi por completo de cómo configures tu agente. Ese prompt de sistema, que es absolutamente necesario para cualquier caso de uso empresarial, es el factor más importante que dispara tu factura. Esta volatilidad hace que sea difícil presupuestar y escalar un proyecto de IA de voz.
Más allá de las tarifas de la API: los otros costes de crear un agente de IA de voz
La factura de la API es solo una parte de la ecuación. Si planeas construir un agente de voz desde cero con la API Realtime, los costes reales están ocultos en las horas de ingeniería que se necesitan para tenerlo listo para los clientes.
Cómo la ingeniería de prompts afecta a tus costes
Conseguir que una IA siga instrucciones de forma fiable es más difícil de lo que parece. Escribir un buen prompt de sistema implica mucho ensayo y error. Un prompt descuidado lleva a una IA confundida, lo que se traduce en clientes frustrados y dinero tirado a la basura.
Y no es solo el prompt. Tienes que proporcionar a la IA la información correcta. Eso significa construir un sistema para conectarla a los artículos de tu centro de ayuda, wikis internas y documentos de productos. Esto supone un gran esfuerzo de ingeniería que requiere configurar canalizaciones de datos y sistemas de recuperación.
Aquí es donde una herramienta como eesel AI resulta útil. Te ofrece un editor de prompts sencillo y se conecta automáticamente a tus fuentes de conocimiento. Puedes vincular tu Zendesk, Confluence o Google Docs con solo unos clics, sin necesidad de programar.

Costes de integración
Un agente de voz que en realidad no puede hacer nada no es de mucha ayuda. Para ser útil, tiene que conectarse a tus otros sistemas empresariales. Necesita poder crear un ticket en tu servicio de asistencia, comprobar el estado de un pedido en Shopify o transferir una conversación a un humano en Slack.
Construir estas integraciones por ti mismo significa código personalizado, gestionar claves de API y manejar la autenticación para cada herramienta. Es un montón de trabajo, y tienes que mantenerlo para siempre. En cambio, eesel AI tiene integraciones con un solo clic con docenas de herramientas empresariales comunes, lo que permite a tu agente tomar medidas desde el primer día sin que tengas que escribir ningún código.
El riesgo de lanzar sin pruebas adecuadas: un coste oculto
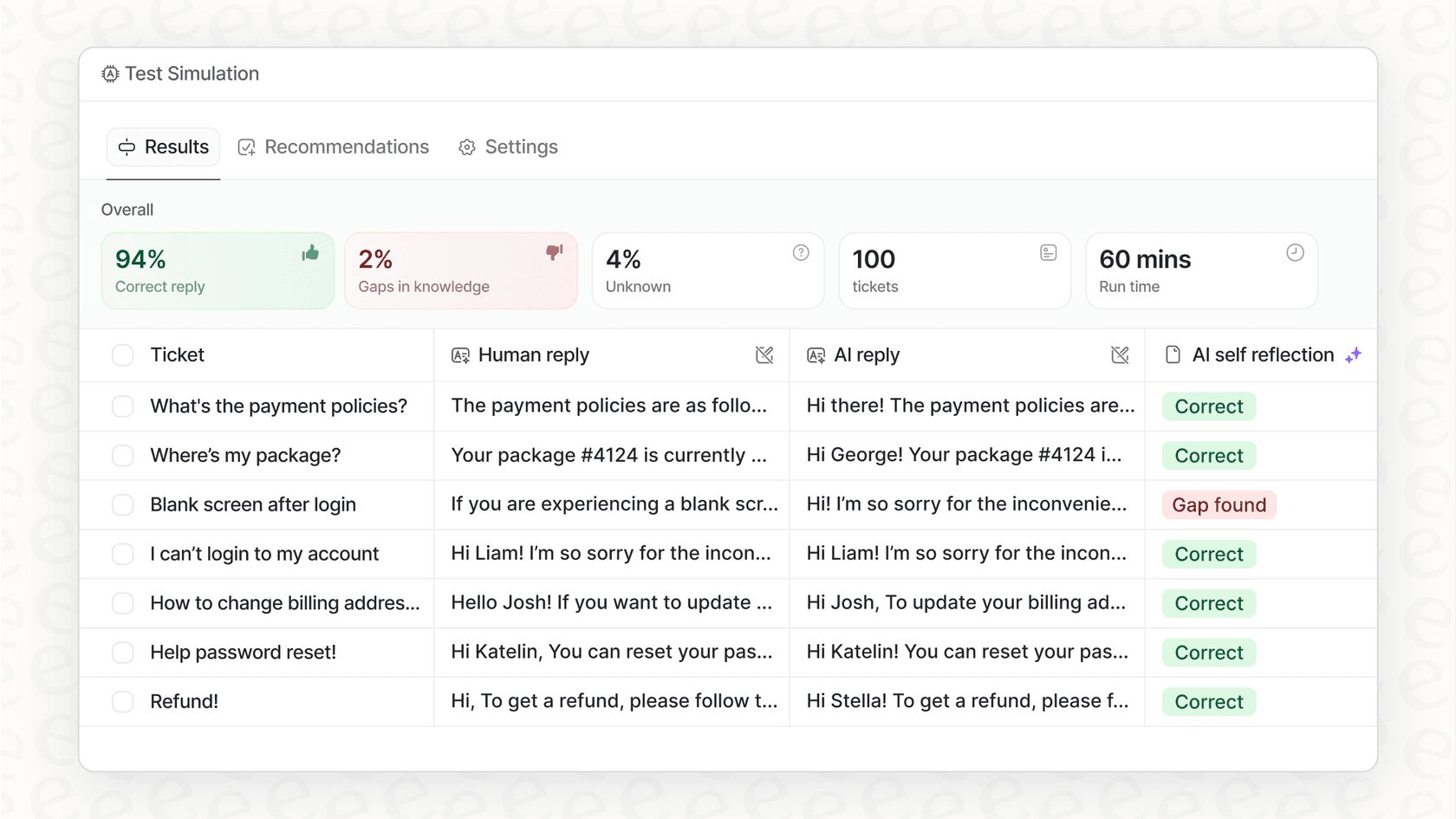
¿Cómo sabes si tu agente está listo para el gran público antes de dejar que hable con clientes reales? Si lo estás construyendo tú mismo, la respuesta honesta suele ser: no lo sabes.
Configurar un entorno de pruebas adecuado para simular conversaciones reales a escala es un proyecto enorme por sí solo. Pero realmente no quieres soltar una IA no probada sobre tu base de clientes. Es un riesgo masivo para tu reputación.
El agente de IA de eesel AI ayuda a resolver esto con un modo de simulación. Puedes probar tu agente con miles de tus conversaciones de soporte pasadas para ver exactamente cómo las habría manejado. Esto te da una visión clara y basada en datos de cómo funcionará y cuál podría ser tu retorno de la inversión, para que puedas lanzarlo sin cruzar los dedos.
Una alternativa más inteligente: costes predecibles y despliegue más rápido
En lugar de luchar con los tokens y construir todo desde cero, usar una plataforma de IA todo en uno es un camino mucho mejor para la mayoría de los equipos. No solo es más barato a largo plazo, sino que también es mucho más rápido.
Lanza tu agente en una tarde
Un agente de voz personalizado puede llevar a un equipo de ingenieros semanas o incluso meses en construirlo. Con eesel AI, puedes estar en funcionamiento por tu cuenta en unas pocas horas. Toda la plataforma está diseñada para ser autoservicio. Puedes conectar tus conocimientos, configurar la personalidad y las reglas de tu agente, y ejecutar simulaciones sin tener que programar una demostración.
Obtén el control con precios predecibles y transparentes
El mayor problema de usar la API directamente es que nunca sabes cuál será tu factura. una semana de mucho trabajo podría resultar en una factura sorprendentemente alta. eesel AI ofrece planes transparentes basados en un número fijo de interacciones de IA mensuales. Sabes exactamente lo que pagas cada mes, así que no hay sorpresas desagradables.
Además, obtienes un control detallado. Puedes establecer reglas que definan exactamente qué preguntas maneja la IA y cuáles se envían directamente a un humano. Esto te permite empezar poco a poco, automatizando primero las tareas fáciles y repetitivas, y luego escalar con confianza a medida que avanzas, todo mientras mantienes tus costes bajo control.

De precios confusos a un claro valor empresarial
Aunque el precio bruto de GPT realtime mini parece barato a primera vista, la realidad de la facturación basada en tokens es una montaña rusa de costes impredecibles. Además, las tarifas de la API son solo una pequeña parte del coste real de construir un agente de voz. La verdadera inversión es la montaña de trabajo de ingeniería necesaria para el ajuste de prompts, las integraciones y las pruebas.
Una plataforma como eesel AI ofrece un enfoque mucho más sensato. Utiliza modelos potentes como GPT-4o mini pero se encarga de toda la complejidad por ti. Al ofrecer una plataforma de autoservicio con integraciones de un solo clic, pruebas potentes y precios predecibles, eesel AI te brinda una forma más rápida, segura y asequible de lanzar agentes de IA que realmente ayuden a tu negocio.
¿Listo para ver lo sencillo que puede ser? Deja de preocuparte por los tokens y empieza a automatizar. Prueba eesel AI gratis y pon en marcha tu primer agente en minutos.
Preguntas frecuentes
¿Por qué es difícil entender los precios de GPT realtime mini con la facturación basada en tokens?
La facturación basada en tokens dificulta la predicción de los costes porque variables como la duración de las llamadas, la proporción entre entradas y salidas y la inclusión constante de prompts de sistema fluctúan significativamente. Estos factores se combinan para hacer que la previsión de tus gastos sea un reto considerable.
¿Cómo afecta un prompt de sistema a los precios de GPT realtime mini?
Los prompts de sistema pueden aumentar drásticamente los costes porque se envían como tokens de entrada en cada turno de una conversación. Nuestras pruebas demostraron que un prompt detallado de 1000 palabras puede más que duplicar el coste por minuto en comparación con un agente sin instrucciones.
¿Cuál es un coste medio por minuto realista para los precios de GPT realtime mini, considerando una configuración empresarial estándar?
Nuestro desglose práctico encontró que con un prompt de sistema necesario de 1000 palabras, el coste medio para GPT-4o mini puede ser de alrededor de 0,33 $ por minuto. Aunque un escenario sin prompt es más barato, a ~0,16 $, no representa una aplicación empresarial útil.
Además de las tarifas directas de la API, ¿qué otros costes ocultos están asociados con los precios de GPT realtime mini al construir un agente de voz?
Más allá de las tarifas de la API, los costes ocultos significativos incluyen extensas horas de ingeniería para el ajuste de prompts, la construcción de integraciones complejas con los sistemas empresariales existentes y el desarrollo de entornos de prueba adecuados. Estos esfuerzos son cruciales pero a menudo se pasan por alto en las estimaciones iniciales de costes.
¿Existe una alternativa al uso directo de la API que ofrezca precios más predecibles para GPT realtime mini?
Sí, las plataformas de IA todo en uno como eesel AI ofrecen planes de precios transparentes y predecibles, generalmente basados en un número fijo de interacciones mensuales de IA. Este enfoque elimina la volatilidad de la facturación basada en tokens, lo que permite una mejor gestión del presupuesto y evita facturas sorpresa.
¿Cómo puede ayudar una plataforma a reducir el tiempo y el esfuerzo asociados con la gestión de los precios y el despliegue de GPT realtime mini?
Plataformas como eesel AI reducen drásticamente el tiempo y el esfuerzo de despliegue a través de una configuración de autoservicio, integraciones con un solo clic y funciones de prueba integradas. Esto permite a los equipos poner en marcha los agentes en horas en lugar de semanas o meses de desarrollo personalizado, simplificando la gestión de costes y las operaciones.