
Fragen in einen Chatbot einzutippen, fühlt sich mittlerweile ganz normal an, oder? Aber das nächste große Ding in der KI ist nicht das Tippen, sondern das Sprechen. Wir stehen kurz davor, konversationelle Sprach-KI in Echtzeit zu haben, die uns verstehen, bei Bedarf unterbrechen und genau wie ein Mensch antworten kann. Es ist ein Wandel, der eine viel natürlichere Art der Interaktion mit Technologie verspricht.
Angetrieben wird diese Entwicklung von Tools wie der OpenAI Realtime API, die Entwicklern die Bausteine für diese flüssigen, sprachgesteuerten Erlebnisse an die Hand gibt. Aber die Sache ist die: Während die Technologie an sich unglaublich ist, ist es eine ganz andere Geschichte, sie in ein ausgereiftes, praxistaugliches Business-Tool zu verwandeln. Dieser Weg erfordert in der Regel fundiertes technisches Know-how, viele Entwicklungsstunden und eine gehörige Portion Geduld.
Werfen wir also einen Blick hinter die Kulissen der OpenAI Realtime API, sehen wir uns an, was sie kann, und sprechen wir offen darüber, was es braucht, um damit zu entwickeln.
Was ist die OpenAI Realtime API?
Im Kern ist die OpenAI Realtime API ein Werkzeug, das es Entwicklern ermöglicht, Anwendungen mit Sprach-zu-Sprach-Konversationen mit geringer Latenz zu erstellen. Wenn Sie jemals den erweiterten Sprachmodus von ChatGPT verwendet haben, ist dies die Engine, die diese Art von Interaktion ermöglicht – nur dass sie jetzt für jeden verfügbar ist.
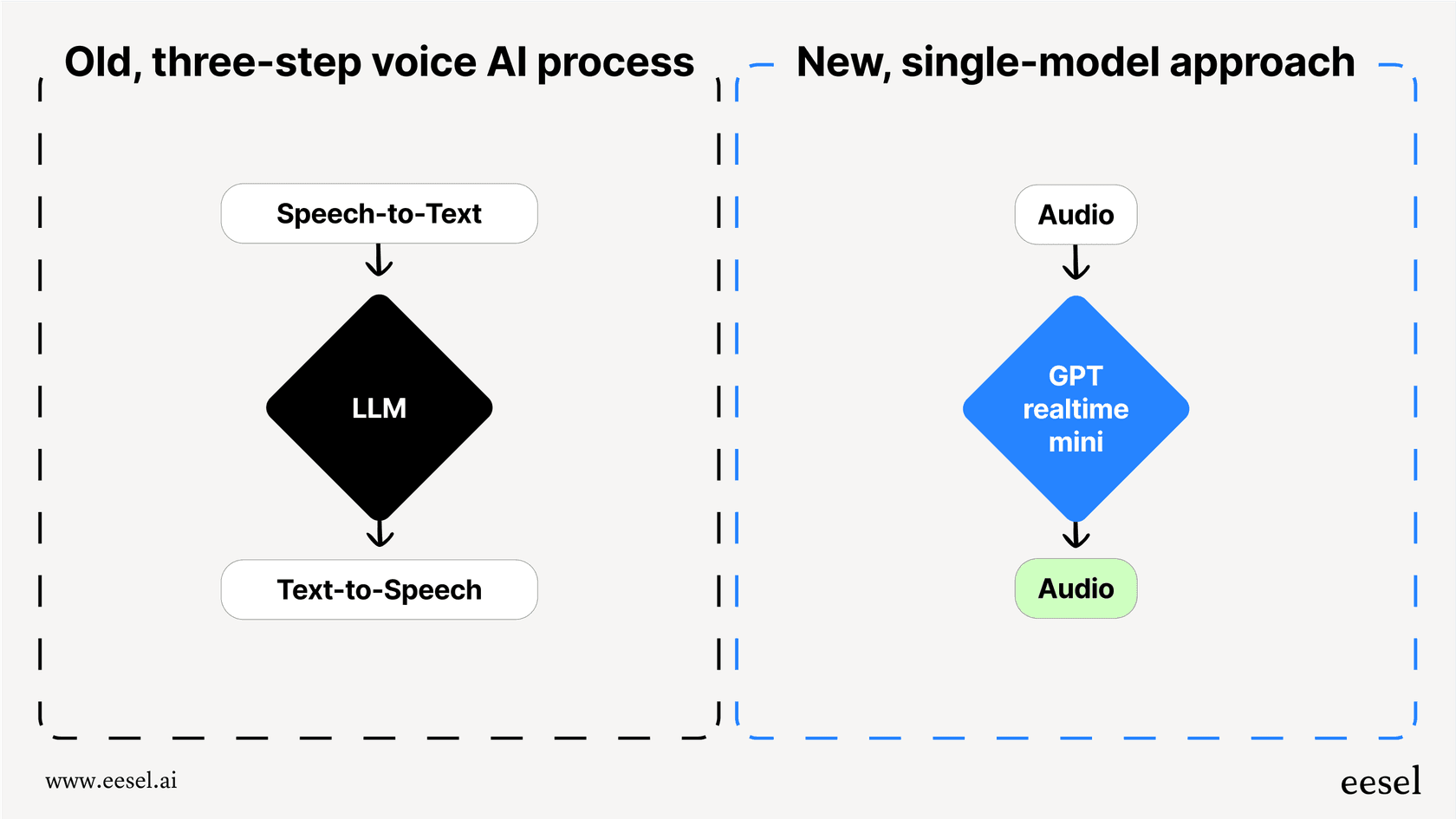
Bevor es diese API gab, war die Erstellung eines Sprachagenten ein umständliches, mehrstufiges Unterfangen. Man musste mehrere verschiedene APIs miteinander verketten:
-
Spracherkennung (Speech-to-Text, STT): Zuerst musste man eine API wie Whisper verwenden, um die gesprochenen Worte des Nutzers in Text umzuwandeln.
-
Großes Sprachmodell (Large Language Model, LLM): Als Nächstes schickte man diesen Text an eine API wie GPT-4, um eine Antwort zu formulieren.
-
Text-zu-Sprache (Text-to-Speech, TTS): Schließlich nutzte man eine weitere API, um die Textantwort wieder in Audio umzuwandeln.
Diese Kette von Ereignissen funktionierte, war aber langsam. Jede Übergabe fügte eine kleine Verzögerung hinzu, was zu einer unangenehmen Latenz führte und Gespräche stockend und unnatürlich wirken ließ. Noch wichtiger ist, dass dabei alle Nuancen der menschlichen Sprache verloren gingen. Dinge wie Tonfall, Emotionen und Betonung verschwanden in dem Moment, in dem Audio zu Text wurde, und übrig blieb eine flache, roboterhafte Interaktion.
Die Realtime API ändert dies grundlegend, indem sie ein einziges, einheitliches Modell (wie „gpt-realtime“) verwendet, das Audio von Anfang bis Ende verarbeitet. Es hört sich Audiodaten an und erzeugt direkt eine Audioantwort. Dies reduziert die Latenz drastisch und bewahrt den Reichtum der Sprache, was den Weg für eine schnellere, ausdrucksstärkere und wirklich konversationelle KI ebnet.
Wie die OpenAI Realtime API funktioniert
Bei der API geht es nicht nur um Sprache; sie ist für multimodale Kommunikation mit geringer Latenz konzipiert. Das ist eine umständliche Art zu sagen, dass sie verschiedene Arten von Informationen gleichzeitig verarbeiten kann, was die Agenten, die Sie entwickeln, viel intelligenter und sich ihrer Umgebung bewusster macht.
Multimodale Fähigkeiten der OpenAI Realtime API
Die Realtime API läuft auf Modellen wie GPT-4o, die „nativ multimodal“ sind. Stellen Sie es sich so vor: Die KI hat nicht nur gelernt, Text zu lesen. Sie wurde von Anfang an darauf trainiert, eine Mischung aus Audio, Bildern und Text gemeinsam zu verstehen und zu verarbeiten. Dies ermöglicht Interaktionen, die weitaus dynamischer sind, als es ein reiner Sprachagent jemals schaffen könnte.
Verbindungsmethoden
Um diese Echtzeitgeschwindigkeit zu erreichen, müssen Sie eine ständige Verbindung zur API offenhalten. OpenAI bietet einige Verbindungsmethoden, und die richtige Wahl hängt wirklich davon ab, was Sie entwickeln und welchen Tech-Stack Ihr Team verwendet.
| Verbindungsmethode | Idealer Anwendungsfall | Technischer Aufwand |
|---|---|---|
| WebRTC | Browser- und clientseitige Apps, die die absolut niedrigste Latenz benötigen. | Hoch (beinhaltet die Verwaltung von Peer-Verbindungen und SDP-Angeboten/-Antworten). |
| WebSocket | Serverseitige Apps, bei denen eine geringe Latenz dennoch Priorität hat. | Mittel (einfacher als WebRTC, erfordert aber dennoch die Verwaltung einer dauerhaften Verbindung). |
| SIP | Integration in VoIP-Telefonsysteme (z. B. in einem Callcenter). | Hoch (erfordert Kenntnisse über Telefonieprotokolle und -infrastruktur). |
Allein die Auswahl und Einrichtung der richtigen Verbindungsmethode ist keine Kleinigkeit. Es erfordert einiges an technischer Planung und Entwicklungsaufwand und ist oft eine der ersten Hürden, auf die Teams stoßen, wenn sie versuchen, einen benutzerdefinierten Sprachagenten zu erstellen.
Wichtige Funktionen der OpenAI Realtime API
Über ihr Kerndesign hinaus enthält die Realtime API eine Reihe von Funktionen, die sie zu einem leistungsstarken Toolkit für Entwickler machen. Dies sind die Bausteine, die Sie verwenden werden, um intelligente und dynamische Sprachagenten zu erstellen.
Sprach-zu-Sprach-Interaktion
Das ist das Hauptereignis. Da ein Modell wie „gpt-realtime“ direkt mit Audio arbeitet, kann es subtile Hinweise wie Lachen, Sarkasmus oder emotionale Veränderungen aufgreifen, die textbasierten Systemen immer entgehen. Es kann dann eine Antwort generieren, die viel natürlicher und ausdrucksstärker klingt. Mit der allgemeinen Veröffentlichung der API hat OpenAI sogar zwei neue Stimmen, Marin und Cedar, hinzugefügt, die exklusiv hier verfügbar sind und unglaublich realistisch klingen.
Sprachaktivitätserkennung (VAD)
Die Sprachaktivitätserkennung (Voice Activity Detection, VAD) sorgt dafür, dass sich ein KI-Gespräch weniger wie eine Transaktion und mehr wie ein echtes Gespräch anfühlt. Es ist die Funktion, die der KI mitteilt, wann jemand zu sprechen beginnt oder aufhört. Dies ist für einen natürlichen Gesprächsfluss unerlässlich. Wenn ein Benutzer einspringen und das Thema wechseln möchte, kann er einfach anfangen zu sprechen. Der Agent erkennt dies und passt sich an, anstatt stur weiterzumachen oder auf eine peinliche Pause zu warten.
Funktionsaufrufe und Tools
Ein Sprachagent ist nur dann nützlich, wenn er auch tatsächlich tun kann. Die Realtime API unterstützt Funktionsaufrufe, die es dem Agenten ermöglichen, sich mit externen Tools und Datenquellen zu verbinden, um Informationen abzurufen oder Aufgaben zu erledigen. Beispielsweise könnte ein Support-Agent eine Funktion verwenden, um den Bestellstatus eines Kunden in Ihrem System nachzuschlagen oder eine Rückerstattung direkt zu bearbeiten. Obwohl dies unglaublich leistungsstark ist, liegt es an Ihnen als Entwickler, jede einzelne dieser Tool-Integrationen zu erstellen, zu verbinden und zu warten.
Bild- und Texteingaben
Da die API multimodal ist, sind die Nutzer nicht nur auf ihre Stimme beschränkt. Sie können dem Gespräch auch andere Informationen hinzufügen. Ein Kunde könnte während eines Anrufs mit einem Support-Agenten einen Screenshot einer Fehlermeldung senden und fragen: „Was sehe ich hier?“ Der Agent kann das Bild sehen, den Kontext verstehen und eine hilfreiche mündliche Antwort geben.
Häufige Anwendungsfälle und Einschränkungen der OpenAI Realtime API
Das Potenzial für Sprach-KI mit geringer Latenz ist riesig, aber einige Anwendungsfälle haben sich schnell zu den beliebtesten entwickelt. Es ist auch wichtig, realistisch zu sein, was die Hürden angeht, die beim Erstellen dieser Anwendungen von Grund auf zu überwinden sind.
Anwendungsfälle
-
Kundensupport-Agenten: Beantwortung eingehender Anrufe, Bearbeitung häufiger Fragen und Weiterleitung komplexerer Probleme an den richtigen menschlichen Mitarbeiter.
-
Persönliche Assistenten: Hilfe bei der Terminplanung, dem Setzen von Erinnerungen und dem freihändigen Abrufen von Informationen.
-
Sprachlern-Apps: Erstellung realistischer Gesprächspartner, die Nutzern helfen, das Sprechen einer neuen Sprache zu üben.
-
Bildungstools: Entwicklung interaktiver Tutoren, die komplexe Themen mündlich erklären und Fragen von Schülern beantworten können.
Einschränkungen des DIY-Ansatzes
Die Entwicklung eines Sprachagenten mit der reinen API mag spannend klingen, aber es ist ein riesiges Ingenieurprojekt, bei dem es um viel mehr geht als nur den Aufruf eines Endpunkts.
-
Der Entwicklungsaufwand ist enorm: Sie binden nicht nur eine API ein, sondern entwickeln eine komplette Anwendung. Das bedeutet, die Infrastruktur zu verwalten, den Gesprächszustand zu handhaben, die Logik zu entwerfen und sicherzustellen, dass das gesamte System zuverlässig und skalierbar ist.
-
Keine Geschäftsworkflows enthalten: Die API gibt Ihnen den Motor, aber Sie müssen das Auto bauen. Die gesamte geschäftsspezifische Logik für die Triage von Tickets, die Eskalation an das richtige Team, die Nachverfolgung von Interaktionen und das Reporting über die Leistung muss von Grund auf neu entwickelt werden.
-
Keine integrierten Analysen oder Tests: Woher wissen Sie, ob Ihr Agent wirklich gut ist? Ohne spezielle Tools gibt es keine einfache Möglichkeit, Ihren Agenten mit vergangenen Gesprächen zu testen, seine Genauigkeit zu messen oder herauszufinden, wo Ihre Wissensdatenbank Lücken aufweist.
Hier kommt die klassische „Build vs. Buy“-Debatte ins Spiel. Für Teams, die eine produktionsreife KI-Supportlösung benötigen, ohne monatelang auf die Entwicklung zu warten, bietet eine Plattform wie eesel AI einen viel direkteren Weg. Sie bietet eine No-Code-Workflow-Engine, Ein-Klick-Helpdesk-Integrationen und leistungsstarke Simulationstools, mit denen Sie in Minuten statt Monaten live gehen können.
Preise der OpenAI Realtime API
Die Preise für die API basieren auf Audio-Token, die anders als Text-Token berechnet werden. Ihnen wird sowohl das an das Modell gesendete Audio (Input) als auch das vom Modell zurückgesendete Audio (Output) in Rechnung gestellt. Das kann die Kostenprognose erschweren, da die Kosten von der Länge und Komplexität jedes Gesprächs abhängen.
Hier ist ein kurzer Überblick über die Preise für das „gpt-realtime“-Modell (Standard-Stufe), das 20 % günstiger ist als die Vorschauversion:
| Token-Typ | Preis pro 1 Mio. Token |
|---|---|
| Audio-Input | $32.00 |
| Gecachter Audio-Input | $0.40 |
| Audio-Output | $64.00 |
(Preisinformationen basierend auf der Preisseite von OpenAI.)
Während die tokenbasierte Preisgestaltung für Entwickler, die nur experimentieren, flexibel ist, kann sie für Unternehmen mit hochvolumigen Supportkanälen zu unvorhersehbaren Rechnungen führen. Ein geschäftiger Monat könnte zu einer überraschend hohen Rechnung führen, was eine effektive Budgetierung erschwert.
Die einfachere Alternative zur OpenAI Realtime API: KI-Support-Agenten mit eesel AI
Direkt mit der OpenAI Realtime API zu entwickeln ist eine fantastische Option für Entwickler, die brandneue Anwendungen von Grund auf erstellen. Für Unternehmen, die jedoch den Kundensupport automatisieren, ihr IT-Service-Management verbessern oder interne F&A-Systeme betreiben möchten, ist eine dedizierte Plattform fast immer die schnellere, kostengünstigere und leistungsfähigere Wahl.
eesel AI ist eine komplette KI-Support-Plattform, die die Leistung fortschrittlicher Modelle wie denen hinter der Realtime API nutzt, Ihnen aber erspart, auch nur eine einzige Zeile Code für Integrationen oder Workflow-Management schreiben zu müssen.
So begegnet sie den Herausforderungen des DIY-Ansatzes:
-
In Minuten live gehen: Anstatt Monate mit WebSockets und Infrastruktur zu kämpfen, können Sie Ihren Helpdesk (wie Zendesk, Freshdesk oder [Intercom]) und Ihre Wissensquellen mit einem einzigen Klick verbinden. Ihr KI-Agent kann sofort damit beginnen, aus Ihren vergangenen Tickets, Hilfeartikeln und internen Dokumenten zu lernen.
-
Sicher testen: Der Simulationsmodus von eesel AI ermöglicht es Ihnen, Ihren Agenten in einer sicheren Umgebung an Tausenden Ihrer echten historischen Tickets zu testen. Sie können sehen, wie er reagiert hätte, sein Verhalten anpassen und genaue Prognosen zu Lösungsraten und Kosteneinsparungen erhalten, bevor er jemals mit einem echten Kunden interagiert.
-
Vollständige Kontrolle und Anpassung: Mit einem einfachen Prompt-Editor und einer No-Code-Workflow-Engine entscheiden Sie genau, welche Tickets Ihre KI bearbeitet und welche Aktionen sie ausführen kann. Sie können Regeln einrichten, um komplexe Probleme zu eskalieren, Tickets automatisch zu kennzeichnen oder sogar externe APIs aufzurufen, um Bestellinformationen abzurufen.
-
Vorhersehbare Preise: Die Pläne von eesel AI basieren auf einer festen Anzahl monatlicher KI-Interaktionen, ohne überraschende Gebühren pro Lösung. Das macht Ihr Budget einfach und transparent und beseitigt das Rätselraten, das mit einem variablen, tokenbasierten Modell einhergeht.
Abschließende Gedanken zur OpenAI Realtime API
Die OpenAI Realtime API ist eine wirklich beeindruckende Technologie. Sie schließt die Lücke zwischen der Kommunikation von Menschen und Maschinen und ebnet den Weg für eine Zukunft, in der sich sprachgesteuerte KI vollkommen natürlich anfühlt. Sie gibt Entwicklern eine unglaublich leistungsstarke Engine an die Hand, um erstaunliche Dinge zu erschaffen.
Der Weg von einem API-Schlüssel zu einem zuverlässigen, produktionsreifen Geschäftstool ist jedoch lang und voller technischer Herausforderungen. Für die meisten Unternehmen, insbesondere solche mit Fokus auf Kundenservice und IT-Support, liefert eine speziell für diesen Zweck entwickelte Plattform einfach schneller und zuverlässiger einen Mehrwert. Sie erhalten die gesamte Leistung der zugrunde liegenden KI, verpackt in einer Reihe von Werkzeugen, die genau für die Aufgabe entwickelt wurden, die Sie erledigen müssen.
Sind Sie bereit zu sehen, was ein zweckgebundener KI-Support-Agent für Sie tun kann? Starten Sie Ihre kostenlose Testversion mit eesel AI und automatisieren Sie Ihren First-Line-Support in wenigen Minuten.
Häufig gestellte Fragen
Die OpenAI Realtime API wurde entwickelt, um Entwicklern die Erstellung von Anwendungen zu ermöglichen, die Sprach-zu-Sprach-Konversationen mit geringer Latenz unterstützen. Sie nutzt ein einziges, einheitliches Modell zur direkten Verarbeitung von Audio, was flüssige und natürliche sprachgesteuerte Erlebnisse ermöglicht.
Im Gegensatz zu früheren, mehrstufigen Ansätzen verarbeitet die OpenAI Realtime API Audio von Anfang bis Ende, was die Latenz erheblich reduziert und subtile Hinweise wie Tonfall und Emotionen bewahrt. Diese einheitliche Verarbeitung führt zu weitaus natürlicheren und ausdrucksstärkeren KI-Interaktionen.
Um Echtzeitgeschwindigkeit zu gewährleisten, unterstützt die OpenAI Realtime API mehrere Verbindungsmethoden. Dazu gehören WebRTC für browserbasierte Anwendungen, WebSockets für den serverseitigen Einsatz und SIP für die Integration in VoIP-Telefonsysteme.
Ja, die OpenAI Realtime API unterstützt Funktionsaufrufe, die es dem KI-Agenten ermöglichen, sich mit externen Tools und Datenquellen zu verbinden. Entwickler sind für die Erstellung, Anbindung und Wartung dieser Integrationen verantwortlich, um bestimmte Aufgaben oder Informationsabrufe zu ermöglichen.
Die Preise der OpenAI Realtime API basieren auf Audio-Token für Input und Output, was die Kostenprognose erschweren kann. Für Unternehmen mit hohem Nutzungsvolumen kann dieses tokenbasierte Modell zu variablen und potenziell hohen monatlichen Rechnungen führen.
Die OpenAI Realtime API läuft auf nativ multimodalen Modellen wie GPT-4o, wodurch sie eine Mischung aus Audio, Bildern und Text verarbeiten kann. Das bedeutet, dass Benutzer neben ihren gesprochenen Fragen auch visuellen Kontext, wie z. B. einen Screenshot, bereitstellen können, um reichhaltigere und umfassendere Interaktionen zu ermöglichen.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.
