
Es gibt viel Wirbel um die Realtime API von OpenAI, und ehrlich gesagt, das ist verständlich. Die Idee, extrem reaktionsschnelle, menschenähnliche Sprachagenten zu entwickeln, ist ziemlich aufregend. Das Modell, das die meiste Aufmerksamkeit erhält, ist "gpt-4o-mini-realtime", hauptsächlich weil es eine solide Leistung zu einem scheinbar unschlagbar günstigen Preis verspricht.
Aber hier ist der Haken. Sobald man die Preisgestaltungsseite aufruft, wird man mit Fachjargon wie "pro Million Tokens" für Text, Audio und etwas, das als zwischengespeicherte Eingaben bezeichnet wird, konfrontiert. Das lässt die meisten von uns ratlos zurück und wir stellen uns dieselbe Frage: "Okay, aber was kostet mich das tatsächlich pro Minute?"
Wenn Sie herausfinden möchten, ob ein Projekt rentabel ist oder einfach nur ein Budget festlegen wollen, ist die Token-basierte Preisgestaltung ein echtes Ärgernis. Also haben wir beschlossen, die Rechnung für Sie zu machen. Dieser Leitfaden schlüsselt die wahren Kosten für die Nutzung des GPT realtime mini auf und deckt die versteckten Faktoren auf, die Ihre Ausgaben in die Höhe schnellen lassen können, wenn Sie es am wenigsten erwarten.
Die Realtime API von OpenAI verstehen
Bevor wir uns den Zahlen widmen, lassen Sie uns eine gemeinsame Grundlage schaffen. Die OpenAI Realtime API ist ein Werkzeug für Entwickler, die Apps mit schnellen Sprache-zu-Sprache-Konversationen erstellen möchten. Im Grunde ermöglicht sie es Ihnen, eine KI zu schaffen, die fast sofort zuhören und antworten kann, ohne die unangenehme Verzögerung, die man von älterer Technologie kennt.
Sie ist für den Betrieb von Sprachagenten konzipiert. Stellen Sie sich eine KI vor, die Kundendienstanrufe bearbeiten, Termine buchen oder interne Fragen für Ihr Team beantworten kann – und das alles mit einer natürlichen Klangfarbe.
Die API stellt Ihnen einige Modelle zur Verfügung. Es gibt das leistungsstarke "gpt-4o-realtime" für komplexere Chats und sein günstigeres, schnelleres Geschwistermodell, "gpt-4o-mini-realtime". Wir konzentrieren uns hier auf die Mini-Version, weil ihr niedriger Listenpreis sie für viele zum Ausgangspunkt macht.
Das Problem mit der Token-basierten Preisgestaltung von OpenAI
OpenAI berechnet Ihnen jeden "Token", den Ihre App verwendet. Ein Token ist nur ein winziges Datenelement – es könnte ein Wort, eine Silbe oder ein Teil eines Audiosignals sein. Die Kosten basieren darauf, wie viele Tokens Sie an das Modell senden (Eingabe) und wie viele es an Sie zurücksendet (Ausgabe).
Hier ist die offizielle Preisgestaltung für GPT realtime mini von OpenAIs Preisgestaltungsseite:
| Modell & Token-Typ | Eingabepreis (pro 1 Mio. Tokens) | Ausgabepreis (pro 1 Mio. Tokens) |
|---|---|---|
| gpt-4o-mini-realtime-preview | ||
| Text | 0,60 $ | 2,40 $ |
| Audio | 10,00 $ | 20,00 $ |
| Zwischengespeicherte Audio-Eingabe | 0,30 $ | N/A |
Diese Zahlen sehen winzig aus, oder? Aber dieses Modell macht es aus mehreren Gründen unglaublich schwierig, Ihre Kosten vorherzusagen:
-
Anruflängen sind sehr unterschiedlich. Ein kurzes einminütiges Gespräch verbraucht weitaus weniger Tokens als ein komplexer zehnminütiger Supportanruf. Wie können Sie da den Durchschnitt vorhersagen?
-
Das Eingabe-Ausgabe-Verhältnis ändert sich. Ein gesprächiger Kunde und eine schweigsame KI kosten weniger als ein ruhiger Kunde, der lange, detaillierte Erklärungen von der KI benötigt.
-
System-Prompts: Die versteckten Kosten. Das ist der entscheidende Punkt. Um einen Sprachagenten dazu zu bringen, etwas Nützliches zu tun, müssen Sie ihm Anweisungen geben. Dieser "System-Prompt" teilt der KI mit, wer sie ist, was ihre Aufgabe ist und wie sie sich verhalten soll. Dieser gesamte Textblock wird bei jedem einzelnen Austausch in der Konversation als Eingabe-Token gesendet. Ein detaillierter Prompt kann Ihre Kosten leicht verdoppeln oder verdreifachen, und Sie bemerken es vielleicht erst, wenn die Rechnung kommt.
-
Es ist eine Mischung aus Audio und Text. Die API jongliert ständig mit Audio-Tokens (was der Benutzer sagt) und Text-Tokens (was die KI verarbeitet und zurückgibt), und jeder hat seinen eigenen Preis. Diese Mischung verwandelt eine einfache Kostenschätzung in ein Ratespiel.
Eine praktische Kosten-pro-Minute-Aufschlüsselung
Um über die Theorie hinauszugehen, haben wir einige Tests durchgeführt, um zu sehen, wie diese Token-Kosten tatsächlich in Dollar pro Minute aussehen. Wir haben den OpenAI Playground verwendet, um Gespräche zu simulieren, da er Echtzeit-Kostendaten liefert.
Wir haben sowohl das Modell "gpt-4o-mini-realtime" als auch das leistungsstärkere "gpt-4o-realtime" verglichen. Für jedes haben wir einen einfachen Chat und dann einen weiteren mit einem 1.000-Wort-System-Prompt getestet – eine realistische Konfiguration für jedes Unternehmen, dessen KI über Produkte Bescheid wissen oder einem Skript folgen muss.
Die Ergebnisse waren ziemlich überraschend.
| Modell & Konfiguration | Durchschnittliche Kosten pro Minute | Warum das wichtig ist |
|---|---|---|
| GPT-4o mini (Ohne System-Prompt) | ~0,16 $ | Scheint günstig, aber eine KI ohne Anweisungen ist für ein Unternehmen nutzlos. |
| GPT-4o mini (Mit 1.000-Wort-System-Prompt) | ~0,33 $ | Die Kosten mehr als verdoppeln sich allein dadurch, dass man der KI eine grundlegende Anleitung gibt. |
| GPT-4o (Ohne System-Prompt) | ~0,18 $ | Etwas teurer, aber bewältigt komplexe, mehrstufige Gespräche besser. |
| GPT-4o (Mit 1.000-Wort-System-Prompt) | ~1,63 $ | Die Kosten steigen um über 800 %. Genau so werden Budgets gesprengt. |
Die wichtigste Erkenntnis hier ist, dass die beworbenen GPT realtime mini-Preise nur der Ausgangspunkt sind. Ihre tatsächlichen Kosten werden fast ausschließlich davon bestimmt, wie Sie Ihren Agenten konfigurieren. Dieser System-Prompt, den Sie für jeden Geschäftsanwendungsfall unbedingt benötigen, ist der größte Faktor, der Ihre Rechnung in die Höhe treibt. Diese Volatilität macht es schwierig, ein Sprach-KI-Projekt zu budgetieren und zu skalieren.
Jenseits der API-Gebühren: Die anderen Kosten für die Erstellung eines Sprach-KI-Agenten
Die API-Rechnung ist nur ein Teil der Gleichung. Wenn Sie planen, einen Sprachagenten von Grund auf mit der Realtime API zu erstellen, sind die wahren Kosten in den Ingenieursstunden vergraben, die erforderlich sind, um ihn für Kunden einsatzbereit zu machen.
Wie Prompt Engineering Ihre Kosten beeinflusst
Eine KI dazu zu bringen, Anweisungen zuverlässig zu befolgen, ist schwieriger, als es aussieht. Das Schreiben eines guten System-Prompts erfordert viel Ausprobieren. Ein unsauberer Prompt führt zu einer verwirrten KI, was zu frustrierten Kunden und verschwendetem Geld führt.
Und es geht nicht nur um den Prompt. Sie müssen die KI mit den richtigen Informationen füttern. Das bedeutet, ein System zu entwickeln, um sie mit Ihren Hilfe-Center-Artikeln, internen Wikis und Produktdokumenten zu verbinden. Dies ist ein großer technischer Aufwand, der die Einrichtung von Datenpipelines und Abrufsystemen erfordert.
Hier erweist sich ein Tool wie eesel AI als nützlich. Es bietet Ihnen einen unkomplizierten Prompt-Editor und verbindet sich automatisch mit Ihren Wissensquellen. Sie können Ihr Zendesk, Confluence oder Google Docs mit nur wenigen Klicks verknüpfen, ganz ohne Programmierung.

Integrationskosten
Ein Sprachagent, der nicht wirklich etwas tun kann, ist keine große Hilfe. Um nützlich zu sein, muss er sich mit Ihren anderen Geschäftssystemen verbinden. Er muss in der Lage sein, ein Ticket in Ihrem Helpdesk zu erstellen, einen Bestellstatus in Shopify zu überprüfen oder ein Gespräch an einen Menschen in Slack zu übergeben.
Diese Integrationen selbst zu erstellen bedeutet, benutzerdefinierten Code zu schreiben, API-Schlüssel zu verwalten und die Authentifizierung für jedes einzelne Tool zu handhaben. Das ist eine Menge Arbeit, und Sie müssen sie dauerhaft warten. Im Gegensatz dazu bietet eesel AI Ein-Klick-Integrationen mit Dutzenden gängiger Geschäftstools, sodass Ihr Agent vom ersten Tag an Aktionen ausführen kann, ohne dass Sie Code schreiben müssen.
Das Risiko des Starts ohne angemessene Tests: Ein versteckter Kostenfaktor
Woher wissen Sie, ob Ihr Agent für den Einsatz bereit ist, bevor Sie ihn mit echten Kunden sprechen lassen? Wenn Sie ihn selbst entwickeln, lautet die ehrliche Antwort oft: Sie wissen es nicht.
Die Einrichtung einer ordnungsgemäßen Testumgebung zur Simulation realer Gespräche im großen Maßstab ist ein riesiges Projekt für sich. Aber Sie wollen wirklich keine ungetestete KI auf Ihre Kunden loslassen. Das ist ein massives Risiko für Ihren Ruf.
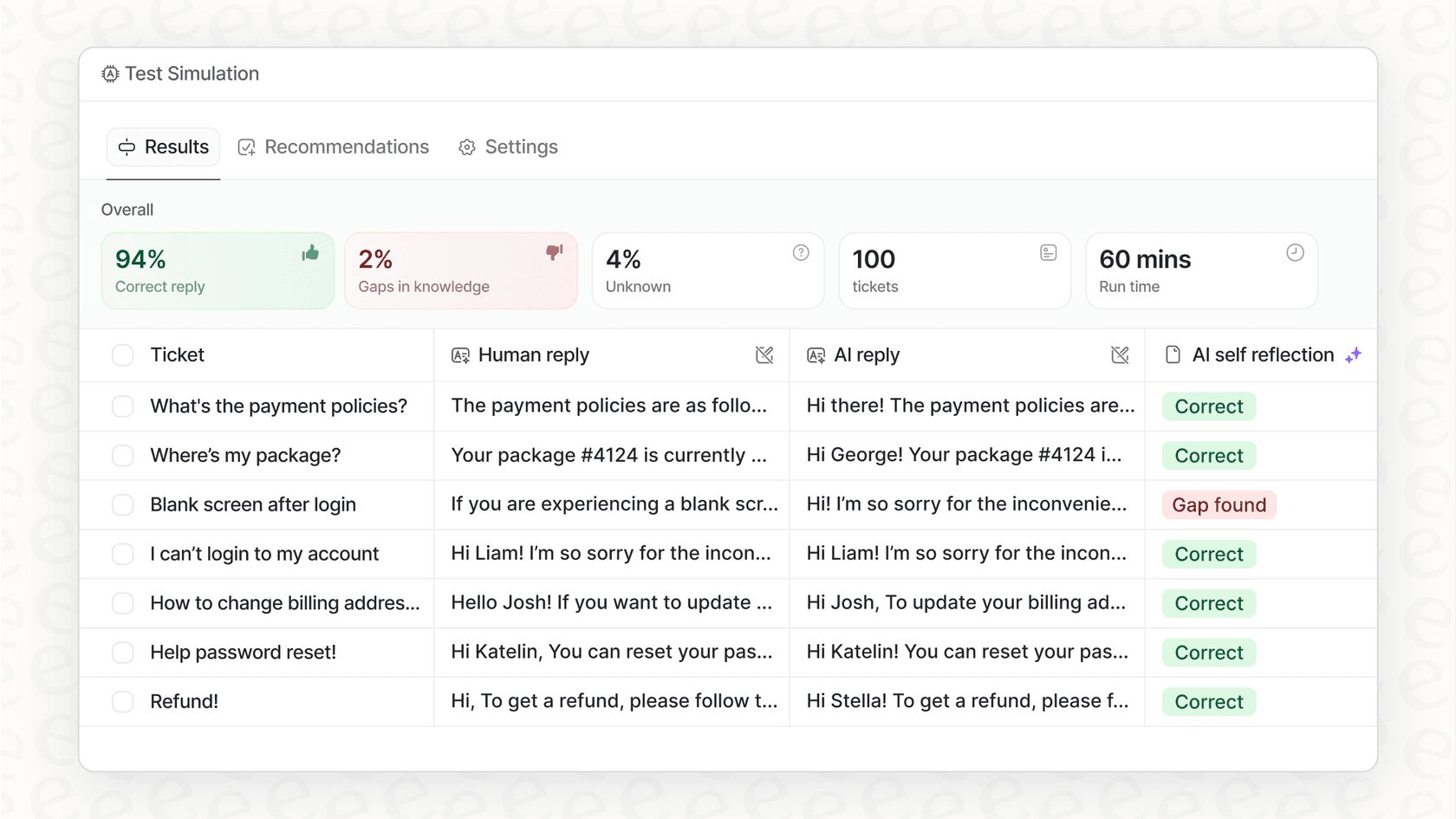
Der KI-Agent von eesel AI hilft, dieses Problem mit einem Simulationsmodus zu lösen. Sie können Ihren Agenten mit Tausenden Ihrer vergangenen Support-Gespräche testen, um genau zu sehen, wie er sie gehandhabt hätte. Dies gibt Ihnen einen klaren, datengestützten Einblick, wie er sich verhalten wird und was Ihr Return on Investment sein könnte, sodass Sie live gehen können, ohne die Daumen drücken zu müssen.
Eine intelligentere Alternative: Vorhersehbare Kosten und schnellere Bereitstellung
Anstatt sich mit Tokens herumzuschlagen und alles von Grund auf neu zu erstellen, ist die Verwendung einer All-in-One-KI-Plattform für die meisten Teams ein weitaus besserer Weg. Es ist nicht nur langfristig günstiger, sondern auch viel schneller.
An einem Nachmittag live gehen
Ein benutzerdefinierter Sprachagent kann ein Team von Ingenieuren Wochen oder sogar Monate in Anspruch nehmen. Mit eesel AI können Sie in wenigen Stunden selbstständig einsatzbereit sein. Die gesamte Plattform ist als Self-Service konzipiert. Sie können Ihr Wissen verbinden, die Persönlichkeit und Regeln Ihres Agenten einrichten und Simulationen durchführen, ohne jemals eine Demo vereinbaren zu müssen.
Kontrolle durch vorhersehbare, transparente Preise
Das größte Problem bei der direkten Nutzung der API ist, dass Sie nie wissen, wie hoch Ihre Rechnung sein wird. Eine geschäftige Woche könnte zu einer überraschend hohen Rechnung führen. eesel AI bietet transparente Pläne, die auf einer festen Anzahl monatlicher KI-Interaktionen basieren. Sie wissen genau, was Sie jeden Monat bezahlen, sodass es keine bösen Überraschungen gibt.
Außerdem erhalten Sie eine fein abgestufte Kontrolle. Sie können Regeln festlegen, die genau definieren, welche Fragen die KI bearbeitet und welche direkt an einen Menschen weitergeleitet werden. So können Sie klein anfangen, indem Sie zuerst die einfachen, sich wiederholenden Aufgaben automatisieren und dann mit Zuversicht skalieren, während Sie Ihre Kosten im Griff behalten.

Von verwirrenden Preisen zu klarem Geschäftswert
Obwohl die reinen Preise für GPT realtime mini auf den ersten Blick günstig erscheinen, ist die Realität der Token-basierten Abrechnung eine Achterbahnfahrt unvorhersehbarer Kosten. Darüber hinaus sind die API-Gebühren nur ein kleiner Teil der wahren Kosten für die Erstellung eines Sprachagenten. Die eigentliche Investition ist der Berg an Ingenieursarbeit, der für Prompt-Tuning, Integrationen und Tests erforderlich ist.
Eine Plattform wie eesel AI bietet einen viel vernünftigeren Ansatz. Sie nutzt leistungsstarke Modelle wie GPT-4o mini, übernimmt aber die gesamte Komplexität für Sie. Durch eine Self-Service-Plattform mit Ein-Klick-Integrationen, leistungsstarken Tests und vorhersehbaren Preisen bietet eesel AI Ihnen einen schnelleren, sichereren und erschwinglicheren Weg, KI-Agenten zu starten, die Ihrem Unternehmen wirklich helfen.
Sind Sie bereit zu sehen, wie einfach es sein kann? Hören Sie auf, sich über Tokens Gedanken zu machen, und beginnen Sie mit der Automatisierung. Testen Sie eesel AI kostenlos und bringen Sie Ihren ersten Agenten in wenigen Minuten live.
Häufig gestellte Fragen
Warum ist es schwierig, die Preise für GPT realtime mini bei Token-basierter Abrechnung zu verstehen?
Die Token-basierte Abrechnung erschwert die Vorhersage der Kosten, da Variablen wie Gesprächsdauer, das Verhältnis von Eingabe zu Ausgabe und die ständige Einbeziehung von System-Prompts stark schwanken. Diese Faktoren zusammen machen die Prognose Ihrer Ausgaben zu einer erheblichen Herausforderung.
Wie stark beeinflusst ein System-Prompt die Preise für GPT realtime mini?
System-Prompts können die Kosten drastisch erhöhen, da sie bei jeder Gesprächsrunde als Eingabe-Tokens gesendet werden. Unsere Tests haben gezeigt, dass ein detaillierter 1.000-Wort-Prompt die Kosten pro Minute im Vergleich zu einem Agenten ohne Anweisungen mehr als verdoppeln kann.
Was sind realistische Durchschnittskosten pro Minute für GPT realtime mini bei einer Standard-Unternehmenskonfiguration?
Unsere praktische Analyse hat ergeben, dass mit einem notwendigen 1.000-Wort-System-Prompt die Durchschnittskosten für GPT-4o mini bei etwa 0,33 $ pro Minute liegen können. Ein Szenario ohne Prompt ist mit ca. 0,16 $ zwar günstiger, stellt aber keine nützliche Geschäftsanwendung dar.
Welche weiteren versteckten Kosten sind neben den direkten API-Gebühren mit den Preisen für GPT realtime mini beim Erstellen eines Sprachagenten verbunden?
Über die API-Gebühren hinaus umfassen erhebliche versteckte Kosten umfangreiche Ingenieursstunden für die Feinabstimmung von Prompts, den Aufbau komplexer Integrationen mit bestehenden Geschäftssystemen und die Entwicklung geeigneter Testumgebungen. Diese Aufwände sind entscheidend, werden aber bei den anfänglichen Kostenschätzungen oft übersehen.
Gibt es eine Alternative zur direkten API-Nutzung, die besser vorhersagbare Preise für GPT realtime mini bietet?
Ja, All-in-One-KI-Plattformen wie eesel AI bieten transparente, vorhersehbare Preispläne, die in der Regel auf einer festen Anzahl monatlicher KI-Interaktionen basieren. Dieser Ansatz eliminiert die Unbeständigkeit der Token-basierten Abrechnung und ermöglicht eine bessere Budgetverwaltung ohne überraschende Rechnungen.
Wie kann die Nutzung einer Plattform helfen, den Zeit- und Arbeitsaufwand für die Verwaltung der Preise und die Bereitstellung von GPT realtime mini zu reduzieren?
Plattformen wie eesel AI reduzieren den Bereitstellungsaufwand und die -zeit drastisch durch eine Self-Service-Einrichtung, Ein-Klick-Integrationen und integrierte Testfunktionen. Dadurch können Teams Agenten in Stunden statt in Wochen oder Monaten individueller Entwicklung live schalten, was die Kostenverwaltung und den Betrieb vereinfacht.








