
Intelligente, datengestützte Entscheidungen zu treffen, ist heute keine nette Zusatzoption mehr, sondern ein entscheidender Faktor, mit dem moderne Unternehmen an der Spitze bleiben. Der Motor für all das ist ein Cloud-Data-Warehouse – der zentrale Ort, an dem all Ihre Analysedaten zu Hause sind. Wenn man sich auf die Suche macht, tauchen immer wieder zwei Namen auf: Amazon Redshift und Google BigQuery. Beide sind Schwergewichte, wurden aber mit sehr unterschiedlichen Konzepten entwickelt.
Die Wahl zwischen den beiden kann sich etwas überwältigend anfühlen. Die beste Entscheidung hängt letztendlich von den Bedürfnissen Ihres Teams, dem Budget und davon ab, wie viel Eigenleistung Sie erbringen möchten. Dieser Leitfaden durchbricht das Durcheinander in der Debatte BigQuery vs. Redshift und vergleicht die beiden in Bezug auf Architektur, Leistung, Preis und die tägliche Nutzung, damit Sie herausfinden können, welche Lösung die richtige für Sie ist.
Was ist ein Cloud-Data-Warehouse?
Stellen Sie sich ein Data Warehouse wie die Zentralbibliothek für alle Daten Ihres Unternehmens vor. Es sammelt Informationen von überall her – Ihrem CRM, Ihren Vertriebstools, Support-Plattformen – und organisiert sie für einen einzigen Zweck: die Analyse.
Vor nicht allzu langer Zeit mussten Unternehmen diese Warehouses auf eigenen Servern in irgendeinem Abstellraum betreiben. Das war teuer, umständlich und bei der Skalierung ein absoluter Albtraum. Der Wechsel in die Cloud hat alles verändert und bietet eine viel günstigere und flexiblere Möglichkeit, riesige Datenmengen zu verarbeiten.
Um zu verstehen, warum das wichtig ist, hilft es, den Unterschied zwischen OLTP- (Online Transaction Processing) und OLAP-Systemen (Online Analytical Processing) zu kennen. Ihre alltäglichen Anwendungen, wie ein Kassensystem, das einen Kauf abwickelt, sind OLTP. Sie sind für viele kleine, schnelle Transaktionen ausgelegt. Data Warehouses sind OLAP-Systeme. Sie sind darauf ausgelegt, riesige Datenmengen zu durchsuchen, um große, komplexe Fragen zu beantworten, wie zum Beispiel: „Welche Marketingkampagne hat uns letztes Jahr die wertvollsten Kunden gebracht?“
Was ist Google BigQuery?
Google BigQuery ist das vollständig verwaltete, serverlose Data Warehouse von Google Cloud. Das Zauberwort hier ist serverless. Sie müssen keinerlei Infrastruktur bereitstellen, konfigurieren oder verwalten. Gar keine. Sie laden einfach Ihre Daten hoch und beginnen, SQL-Abfragen zu schreiben. Hinter den Kulissen ermittelt die Dremel-Engine von Google, wie viel Rechenleistung Sie benötigen, stellt sie bereit und erledigt die Arbeit. Das macht es fantastisch für die spontane Skalierung und die Ausführung riesiger, einmaliger Abfragen ohne jegliche Vorbereitung.
Was ist Amazon Redshift?
Amazon Redshift ist das riesige Petabyte-Data-Warehouse von AWS. Im Gegensatz zu BigQuery ist es ein clusterbasiertes System, was bedeutet, dass Sie einen „Cluster“ bereitstellen müssen, indem Sie die Anzahl und den Typ der benötigten Server (oder Knoten) auswählen. Dieser Ansatz gibt Ihnen eine enorme Kontrolle über Leistung und Kosten und macht es zu einer soliden Wahl für vorhersehbare, berichtslastige Workloads. Außerdem ist es in das riesige AWS-Ökosystem integriert, was ein großer Vorteil ist, wenn Ihr Unternehmen bereits dort angesiedelt ist.
Vergleich von Architektur und Skalierbarkeit
Der größte Unterschied zwischen diesen beiden liegt in ihrer Bauweise. Ihre Architektur bestimmt, wie sie skalieren, wie Sie sie verwalten und letztendlich, ob die Arbeit mit ihnen eine Freude oder ein ständiges Ärgernis ist.
BigQuery's „Es funktioniert einfach“-Serverless-Modell
BigQuery wurde für Einfachheit konzipiert. Es hält Speicher und Rechenleistung komplett getrennt. Wenn Sie eine Abfrage ausführen, weist Google einfach die benötigten Ressourcen (genannt „Slots“) zu, um sie auszuführen. Sobald die Abfrage abgeschlossen ist, werden diese Ressourcen wieder freigegeben.
-
Der Vorteil: Die Skalierung ist mühelos, besonders wenn Ihre Arbeitslast sprunghaft oder unvorhersehbar ist. Sie müssen keine Infrastruktur verwalten, Cluster in der Größe anpassen oder sich um Ausfallzeiten sorgen. Es funktioniert einfach.
-
Der Nachteil: Dieser „Hands-off“-Ansatz bedeutet, dass Sie weniger direkte Kontrolle haben. Bei sehr spezifischen, konsistenten Workloads stellen Sie möglicherweise fest, dass die Leistung nicht so vorhersagbar ist wie bei einem Cluster, den Sie selbst optimiert haben.
Redshifts „Sie haben die Kontrolle“-Clustermodell
Redshift verwendet einen traditionelleren, provisionierten Cluster. Sie entscheiden, wie viele Knoten Sie benötigen und welchen Typs sie sein sollen. Selbst bei neueren Versionen wie den RA3-Knoten, die Speicher und Rechenleistung trennen, verwalten Sie den Rechenteil immer noch als eigenständigen Cluster, den Sie selbst hoch- oder herunterskalieren.
-
Der Vorteil: Sie erhalten eine sehr feingranulare Kontrolle über Leistung und Kosten. Das ist perfekt für stabiles BI-Reporting, bei dem dieselben Abfragen jeden Tag mit derselben Geschwindigkeit ausgeführt werden müssen.
-
Der Nachteil: Mit dieser Kontrolle geht mehr Verantwortung einher. Sie sind für die manuelle Skalierung sowie das Anhalten und Fortsetzen von Clustern verantwortlich, um Geld zu sparen. Dies fügt eine Verwaltungsebene hinzu und erfordert technisches Fachwissen, um Dinge wie Verteilungsschlüssel zu optimieren und Wartungsaufgaben auszuführen, damit alles reibungslos läuft.
Während dieses Maß an Kontrolle für einige großartig ist, geht der allgemeine Trend in der Softwareentwicklung zu einfacheren Tools, die kein ganzes Team von Ingenieuren für den Betrieb benötigen. Plattformen wie eesel AI ermöglichen es beispielsweise Support-Teams, KI-Agenten in Minuten zu erstellen und zu starten, ohne eine einzige Zeile Code anzufassen – eine Aufgabe, die früher Wochen an Entwicklerzeit in Anspruch nahm.
Leistung und gängige Anwendungsfälle
Diese architektonischen Unterschiede haben einen großen Einfluss auf die Leistung der jeweiligen Plattform. Es gibt nicht die eine „schnellere“ Lösung; es hängt wirklich davon ab, was Sie tun.
Wann BigQuery bei der Erkundung riesiger Datensätze glänzt
BigQuery ist darauf ausgelegt, eine riesige Menge paralleler Ressourcen auf eine einzige Abfrage zu konzentrieren. Das macht es unglaublich schnell für Ad-hoc-, explorative Analysen auf riesigen Datenmengen. Wenn Ihr Datenteam ständig neue und komplizierte Fragen stellt, die das Scannen gigantischer Tabellen erfordern, wird sich BigQuery wahrscheinlich wie eine Rakete anfühlen.
- Perfekt für: Data Mining, die Vorbereitung von Daten für Machine-Learning-Modelle und die Ausführung jener gelegentlichen, aber sehr aufwendigen Abfragen. Es ist ein Favorit für Datenwissenschaftler, die einfach nur in die Daten eintauchen wollen, ohne sich um die zugrunde liegende Infrastruktur kümmern zu müssen.
Wo Redshift mit konsistentem BI und Dashboards überzeugt
Die Stärke von Redshift ist seine Konsistenz. Da Sie einen dedizierten Pool an Ressourcen reserviert haben, ist es darauf ausgelegt, eine zuverlässige und schnelle Leistung für dieselben Abfragen immer und immer wieder zu liefern. Sie können es auch mit Dingen wie Sortierschlüsseln (Sort Keys) optimieren, um diese wiederkehrenden Abfragen noch schneller zu machen.
- Perfekt für: Die Bereitstellung von BI-Dashboards in Tools wie Tableau oder Amazon QuickSight, die Erstellung täglicher Finanzberichte und die Verarbeitung vieler gleichzeitiger Benutzer, bei denen eine vorhersagbare Geschwindigkeit entscheidend ist. Es ist oft die erste Wahl für Business-Intelligence-Teams in Unternehmen.
Verwaltung und Benutzerfreundlichkeit
Abgesehen von der reinen Geschwindigkeit lohnt es sich zu überlegen, wie es ist, im Alltag mit jeder Plattform zu arbeiten.
Die Einfachheit von BigQuery
BigQuery ist so konzipiert, dass es fast keine Datenbankadministration erfordert. Es müssen keine Indizes erstellt, keine Bereinigungsbefehle ausgeführt und keine Cluster konfiguriert werden. Sie können innerhalb von Minuten Daten laden und Abfragen ausführen. Außerdem verarbeitet es verschachtelte Daten wie JSON nativ, die Sie für Redshift oft erst „flachklopfen“ müssen, bevor Sie sie laden können.
Der praxisorientierte Ansatz von Redshift
Mit Redshift sitzen Sie am Steuer, was aber auch bedeutet, dass Sie der Mechaniker sind. Sie müssen Knotentypen auswählen, Verteilungs- und Sortierschlüssel zur Optimierung von Abfragen einrichten und gelegentlich Wartungsaufgaben durchführen. Dies gibt erfahrenen Benutzern viele Hebel in die Hand, bedeutet aber auch eine steilere Lernkurve und erfordert oft jemanden mit DBA-Kenntnissen im Team.
BigQuery ist gut, wenn man keine DBA-Expertise oder Ressourcen hat, um einen Cluster zu verwalten. Redshift ist für Fälle, in denen man mehr Kontrolle/Tuning für einen vorhersehbaren Workload benötigt und die Ressourcen dafür hat.
Eine detaillierte Aufschlüsselung der Preise von BigQuery vs. Redshift
Reden wir über Geld. Die Preisgestaltung ist ein riesiger Faktor, und beide Plattformen haben Modelle, die je nach Nutzung entweder sehr günstig oder überraschend teuer sein können.
BigQuery's Pay-per-Use-Modell
BigQuery unterteilt seine Preise in zwei Bereiche: Rechenleistung (Ausführung von Abfragen) und Speicher.
-
Preise für Rechenleistung (Analyse):
- On-Demand: Sie zahlen für die Datenmenge, die Ihre Abfragen scannen. Der Standardtarif beträgt 6,25 $ pro Terabyte (TiB), wobei das erste TiB pro Monat kostenlos ist. Das ist großartig für den Einstieg oder bei unvorhersehbarem Bedarf.
- Kapazität (Editions): Für besser kalkulierbare Kosten können Sie eine feste Menge an Rechenleistung (gemessen in „Slot-Stunden“) reservieren. Dies beginnt bei 0,04 $ pro Slot-Stunde und ist sinnvoll für konsistente Workloads mit hohem Volumen.
-
Preise für Speicher:
- Aktiver Speicher: Sie zahlen etwa 0,02 $ pro GB pro Monat für Daten in Tabellen, die in den letzten 90 Tagen geändert wurden.
- Langzeitspeicher: Wenn eine Tabelle 90 Tage lang nicht angerührt wurde, sinkt der Preis automatisch auf etwa 0,01 $ pro GB pro Monat.
Denken Sie nur daran, dass das Streamen von Daten in BigQuery oder die Nutzung anderer verbundener Dienste eigene Kosten verursachen können.
Redshifts provisioniertes Preismodell
Bei Redshift zahlen Sie hauptsächlich für den von Ihnen eingerichteten Compute-Cluster.
-
Preise für Rechenleistung (Knoten):
- On-Demand: Sie zahlen einen Stundensatz, der auf dem Typ und der Anzahl der Knoten in Ihrem Cluster basiert. Ein beliebter „ra3.xlplus“-Knoten kostet beispielsweise 1,086 $ pro Stunde. Ein großer Vorteil hier ist, dass Sie Ihren Cluster anhalten können, wenn Sie ihn nicht verwenden, um Geld zu sparen.
- Reservierte Instanzen: Bei einer stabilen Arbeitslast können Sie sich für eine Laufzeit von 1 oder 3 Jahren verpflichten, um enorme Rabatte zu erhalten, manchmal bis zu 75 % des On-Demand-Preises.
-
Preise für verwalteten Speicher (für RA3-Knoten):
- Dieser wird getrennt von Ihren Rechenknoten mit etwa 0,024 $ pro GB pro Monat abgerechnet.
-
Serverless-Option: Um besser mit der Einfachheit von BigQuery konkurrieren zu können, bietet Redshift jetzt eine serverlose Option an. Die Abrechnung erfolgt in „Redshift Processing Units“ (RPUs) pro Stunde, beginnend bei 0,36 $ pro RPU-Stunde.
| Merkmal | Google BigQuery | Amazon Redshift |
|---|---|---|
| Hauptmodell | Pay-per-Query (Rechenleistung) + Speicher | Pay-per-Hour (provisionierter Cluster) + Speicher |
| On-Demand-Rechenleistung | 6,25 $ pro gescanntem TiB | Beginnt bei ~$0.543/Stunde pro Knoten |
| Flatrate-Rechenleistung | Ja (Editions, pro Slot-Stunde) | Ja (Reservierte Instanzen, 1-3 Jahre Laufzeit) |
| Speicherkosten | ~$0.02/GB/Monat (aktiv) | ~$0.024/GB/Monat (verwalteter Speicher) |
| Am besten geeignet für | Unvorhersehbare, sprunghafte Workloads | Konsistente, vorhersagbare Workloads |
BigQuery vs. Redshift: Welches Data Warehouse ist das richtige für Sie?
Also, für welche Lösung sollten Sie sich nach all dem entscheiden? Die Entscheidung zwischen BigQuery und Redshift läuft letztendlich auf einen Kompromiss hinaus: Wollen Sie Einfachheit oder wollen Sie Kontrolle?
-
Wählen Sie BigQuery, wenn: Sie weniger Zeit mit der Verwaltung der Infrastruktur und mehr Zeit mit der Analyse von Daten verbringen möchten. Es ist perfekt, wenn Ihre Abfragemuster sehr unterschiedlich sind, Ihr Team im Google-Cloud-Ökosystem zu Hause ist oder Sie Datenwissenschaftler haben, die massive, explorative Abfragen ausführen müssen, ohne ein Ticket bei einem DBA einreichen zu müssen.
-
Wählen Sie Redshift, wenn: Sie eine absolut zuverlässige, vorhersagbare Leistung für Ihre BI-Dashboards und Berichte benötigen. Es ist die bessere Wahl, wenn Ihre Workloads stabil sind, Sie eine feingranulare Kontrolle über die Ressourcen zur Kostenverwaltung wünschen und bereits stark in AWS investiert sind.
Letztendlich gibt es nicht das eine „beste“ Data Warehouse. Das richtige ist das, das zu den Fähigkeiten Ihres Teams, dem Budget Ihres Unternehmens und Ihren tatsächlichen Zielen passt.
Jenseits der Analyse: Das Wissen Ihres Teams vernetzen
Während BigQuery und Redshift hervorragend für die Verarbeitung Ihrer strukturierten Daten geeignet sind, liegt ein großer Teil des wahren Wissens Ihres Unternehmens – alte Support-Tickets, interne Wikis, Projektdokumente – verstreut in unstrukturierten Formaten vor. Hier kann eine KI-Wissensplattform einen gewaltigen Unterschied machen.
eesel AI verbindet sich mit allen Anwendungen und Wissensquellen Ihres Unternehmens, von Helpdesks wie Zendesk und Freshdesk bis hin zu Wikis wie Confluence und Google Docs. Es bündelt all dieses verstreute Wissen, um KI-Agenten zu betreiben, die den Kundensupport automatisieren, Ihren menschlichen Agenten helfen, bessere Antworten zu schreiben und Ihren internen Teams sofortige, genaue Antworten direkt in Slack oder Microsoft Teams geben.
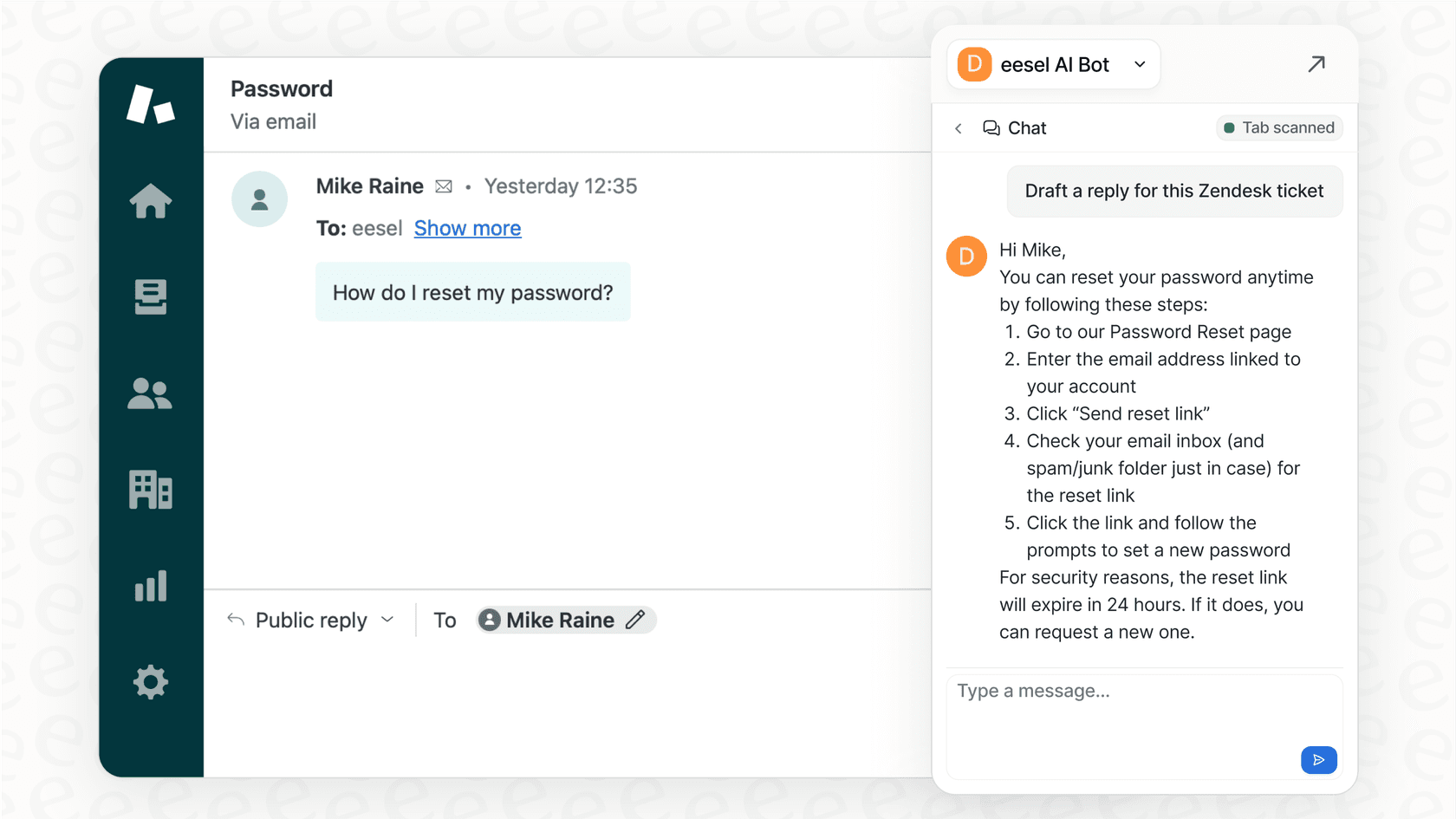
Wenn Sie das kollektive Wissen Ihres Teams in eine automatisierte Support-Engine verwandeln möchten, die wirklich funktioniert, probieren Sie eesel AI kostenlos aus.
Häufig gestellte Fragen
Das serverlose Pay-per-Use-Modell von BigQuery ist bei unbekannten Datenmengen und unvorhersehbaren Abfragemustern im Allgemeinen nachsichtiger. Sie zahlen nur für das, was Sie nutzen, ohne Infrastruktur vorab bereitstellen oder sich über Überprovisionierung Sorgen machen zu müssen.
Das On-Demand-Preismodell von BigQuery, das auf den gescannten Daten basiert, ist bei unregelmäßiger Nutzung besser, da Sie nur zahlen, wenn Abfragen ausgeführt werden. Das traditionelle provisionierte Modell von Redshift mit stündlicher Abrechnung kann in Leerlaufzeiten teurer sein, es sei denn, Sie halten den Cluster manuell an oder nutzen die serverlose Option.
Redshift zeichnet sich durch konsistentes BI-Reporting aus, da sein provisioniertes Clustermodell eine vorhersagbare Leistung für wiederkehrende Abfragen bietet. Die feingranulare Kontrolle ermöglicht eine auf stabile, tägliche Dashboard-Anforderungen zugeschnittene Optimierung (z. B. durch Sortierschlüssel).
BigQuery ist für minimale Verwaltung ausgelegt und erfordert für Einrichtung oder Wartung fast keine DBA-Kenntnisse. Redshift als clusterbasiertes System erfordert mehr manuelle Verwaltung, einschließlich der Auswahl von Knotentypen und der Leistungsoptimierung, was oft von DBA-Expertise profitiert.
BigQuery bietet dank seiner serverlosen Architektur eine mühelose Skalierung, da Ressourcen bei Bedarf automatisch zugewiesen werden. Redshift erfordert eine manuelle Skalierung seiner Cluster, obwohl seine RA3-Knoten und die serverlose Option mehr Flexibilität bieten als ältere Versionen.
Wenn Ihr Unternehmen bereits tief im AWS-Ökosystem verankert ist, bietet Redshift eine nahtlose Integration mit anderen AWS-Diensten wie S3, EC2 und QuickSight. Obwohl BigQuery eine Verbindung zu AWS-Daten herstellen kann, vereinfacht die native Integration in Ihre bestehende Cloud-Umgebung oft den Betrieb.
BigQuery ist besonders gut für die explorative Analyse auf riesigen Datensätzen geeignet, insbesondere wenn diese verschachtelte Strukturen wie JSON enthalten. Seine Architektur ermöglicht es, erhebliche parallele Ressourcen für komplexe Ad-hoc-Abfragen zu nutzen, was es zu einem Favoriten für Datenwissenschaftler macht.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.








