Wir alle wissen, dass eine KI nur so intelligent ist wie die Daten, aus denen sie lernt. Aber wie lernt eine KI tatsächlich, das Problem eines Kunden zu verstehen, herauszufinden, ob er zufrieden oder wütend ist, oder zu wissen, welchen Hilfeartikel sie vorschlagen soll? Das Geheimnis liegt in einem Prozess namens KI-Annotation.
Einfach ausgedrückt, ist KI-Annotation die Aufgabe, Daten zu kennzeichnen, wie Text aus einem Support-Ticket oder ein Bild, damit maschinelle Lernmodelle sie verstehen können. Stellen Sie sich das wie kleine Haftnotizen für einen Computer vor, um ihm beizubringen, was was ist. Während es das Fundament für den Aufbau intelligenter KI ist, ist die altmodische Art, es zu tun, schmerzhaft langsam, teuer und ein großes Ärgernis für jedes Team, das einfach nur einen KI-Support-Agenten zum Laufen bringen möchte.
Dieser Leitfaden führt Sie durch alles, was Sie über KI-Annotation wissen müssen, die Haupttypen, die Sie im Support sehen werden, und die Probleme mit dem traditionellen, manuellen Ansatz. Am wichtigsten ist, dass wir Ihnen zeigen, wie moderne KI-Tools diesen gesamten Prozess der Vergangenheit angehören lassen, sodass Sie eine leistungsstarke KI starten können, ohne ein massives, zeitraubendes Kennzeichnungsprojekt.
Was KI-Annotation ist (und warum sie wichtig ist)
Sie haben wahrscheinlich den Satz "Müll rein, Müll raus" gehört. Wenn es um maschinelles Lernen geht, ist das nicht nur ein Sprichwort; es ist die goldene Regel. Die Leistung eines KI-Modells hängt vollständig von der Qualität seiner Trainingsdaten ab. Wenn Sie einer KI unordentliche, falsche oder unvollständige Informationen zuführen, erhalten Sie unordentliche, falsche und unvollständige Ergebnisse. So einfach ist das.
KI-Annotation ist der Schritt, der einen Berg von rohen, unstrukturierten Daten in einen sauberen, organisierten Datensatz verwandelt, aus dem eine Maschine tatsächlich lernen kann. Es geht darum, den Kontext und die Bedeutung hinzuzufügen, die Maschinen nicht von selbst herausfinden können.
Es ist ein bisschen wie das Training eines neuen Support-Agenten. Sie würden ihm nicht einfach einen Login und einen riesigen Stapel alter Tickets geben und sagen: "Viel Glück!" Sie würden sich mit ihm zusammensetzen, echte Beispiele durchgehen und auf die wichtigen Punkte hinweisen: "Siehst du das? Das ist eine Bestellnummer," "Dieser Kunde ist eindeutig frustriert," oder "Hier fragt er nach einer Rückerstattung." KI-Annotation macht genau dasselbe für eine Maschine, nur in viel größerem Maßstab. Für eine KI im Kundensupport ist dies der Weg, wie sie lernt, ein Ticket zu kategorisieren, den Ton eines Kunden zu verstehen und das eigentliche Problem in einer langen, ausschweifenden E-Mail zu finden.
Häufige Arten der KI-Annotation (mit Fokus auf Support)
Während Sie fast jede Art von Daten annotieren können, gibt es einige Typen, die besonders wichtig für den Aufbau intelligenter Support-Systeme sind. Diese zu verstehen, hilft, klarzumachen, wie eine KI lernt, mit Kundenkonversationen umzugehen.
Text-KI-Annotation: Die Sprache Ihrer Kunden
Für jede Art von Chatbot oder Helpdesk-Automatisierung ist Textannotation König. Es geht darum, einer Maschine beizubringen, die Feinheiten zu erkennen, wie Menschen sprechen und schreiben. Hier sind die Hauptarten, die Sie antreffen werden:
- Absichtserkennung: Hier geht es darum, herauszufinden, was der Kunde eigentlich will. Ein menschlicher Agent weiß sofort, dass "mein Passwort funktioniert nicht," "ich kann mich nicht einloggen," und "ich habe meine Zugangsdaten vergessen" alle dasselbe Problem sind. Die Absichtserkennung ist der Prozess, all diese verschiedenen Phrasen mit einer einzigen Absicht zu kennzeichnen, wie "Passwort zurücksetzen." Dies ist die Kernkompetenz, die es einer KI ermöglicht, Tickets an die richtige Person weiterzuleiten oder den richtigen automatisierten Workflow zu starten.
- Stimmungsanalyse: Dies beinhaltet das Markieren der Emotion in einer Nachricht als positiv, negativ oder neutral. Eine KI muss lernen, dass "Danke, das hat es behoben!" gut ist, während "Ich warte seit drei Tagen auf eine Antwort!" sehr, sehr schlecht ist. Die Kennzeichnung für die Stimmung hilft KI-Agenten, Tickets von verärgerten Kunden zu priorisieren oder sogar ihren eigenen Ton als Reaktion anzupassen.
- Erkennung benannter Entitäten (NER): Dies ist nur ein schicker Begriff dafür, einer KI beizubringen, wichtige Informationen in einem Textblock zu erkennen und zu kennzeichnen. Denken Sie daran, die wichtigen Substantive zu finden: Namen, Bestellnummern, Produktnamen, Orte oder Daten. Wenn ein Kunde schreibt, "Meine Bestellung #12345 ist nicht an meine Adresse in Austin angekommen," ist NER das, was der KI ermöglicht, "#12345" und "Austin" als separate, nützliche Datenstücke herauszuziehen, die sie verwenden kann, um eine Bestellung nachzuschlagen.
Andere relevante Arten der KI-Annotation
Während Text im Support-Bereich das Hauptthema ist, spielen ein paar andere Typen eine nützliche unterstützende Rolle:
- Bild- und Videoannotation: Dies ist nützlich, wenn Kunden Screenshots einer Fehlermeldung oder ein Foto eines defekten Produkts senden. Die Annotation könnte darin bestehen, Kästchen um bestimmte Elemente im Bild zu zeichnen oder einfach das Ganze zu klassifizieren (z. B. "beschädigter Artikel," "UI-Fehler").
- Audioannotation: Dies dreht sich hauptsächlich um die Transkription von Telefonanrufen oder Voicemails in Text. Sobald dieses Audio in Worte umgewandelt ist, können Sie alle zuvor besprochenen Textannotationsmethoden verwenden, um die Absicht, die Stimmung und andere wichtige Details des Kunden zu ermitteln.
Die versteckten Herausforderungen der traditionellen KI-Annotation
Obwohl die Idee, Daten zu kennzeichnen, einfach genug klingt, ist das manuelle Durchführen ein großes Hindernis für die meisten Unternehmen. Es ist einer der größten Gründe, warum so viele KI-Projekte entweder nicht starten oder viel länger dauern als erwartet.
KI-Annotation dauert ewig und kostet ein Vermögen
Das Zusammenstellen eines qualitativ hochwertigen, annotierten Datensatzes ist eine gewaltige Aufgabe. Der Prozess bedeutet normalerweise, Teams von Menschen einzustellen und zu verwalten, die manuell Tausende (oder sogar Hunderttausende) von Kundentickets oder Nachrichten lesen und kennzeichnen. Es gibt ganze Unternehmen, die sich darauf spezialisiert haben, diese Art von Arbeitskräften bereitzustellen. Diese manuelle Arbeit kann sich über Monate hinziehen und ein kleines Vermögen kosten, bevor Sie überhaupt mit dem Training Ihres ersten KI-Modells beginnen.
Die Qualitätskontrolle der KI-Annotation ist ein ständiger Kopfschmerz
Menschen sind subjektiv. Eine Person könnte die Nachricht eines Kunden als "Dringende Funktionsanfrage" kennzeichnen, während jemand anderes sie als "Allgemeines Feedback" sieht. Zu versuchen, ein großes Team perfekt konsistent zu machen, ist nahezu unmöglich. Diese Inkonsistenz führt zu endlosen Überprüfungszyklen und lächerlich langen Anleitungsmanualen, nur um zu versuchen, alle auf die gleiche Seite zu bringen, was den gesamten Prozess noch weiter verlangsamt.
Manuelle KI-Annotation hält nicht mit Ihrem Geschäft Schritt
Ihr Geschäft ändert sich ständig. Sie führen neue Funktionen ein, aktualisieren Richtlinien, und Kunden finden neue Wege, um nach Dingen zu fragen. Jedes Mal, wenn sich etwas ändert, wird Ihre Trainingsdaten ein wenig veraltet. Mit manueller Annotation müssen Sie entweder große Datenmengen neu kennzeichnen oder ein ganz neues Projekt von Grund auf starten. Es schafft einen dauerhaften Engpass, der Ihre KI daran hindert, sich mit Ihrem Geschäft weiterzuentwickeln.
Menschliche Voreingenommenheit in der KI-Annotation kann eine fehlerhafte KI schaffen
Ob wir es beabsichtigen oder nicht, menschliche Annotatoren können ihre eigenen Vorurteile in die Datenkennzeichnungen einbringen. Wenn die Trainingsdaten unbewusste Annahmen über bestimmte Kundentypen widerspiegeln oder bestimmte Probleme konsequent herunterspielen, wird die KI diese gleichen Vorurteile lernen. Dies kann zu einer KI führen, die unfaire oder inkonsistente Antworten gibt und eine schlechte Erfahrung für Ihre Kunden schafft.
Der moderne Ansatz der KI-Annotation: Wie man eine leistungsstarke KI ohne manuelle Annotation erhält
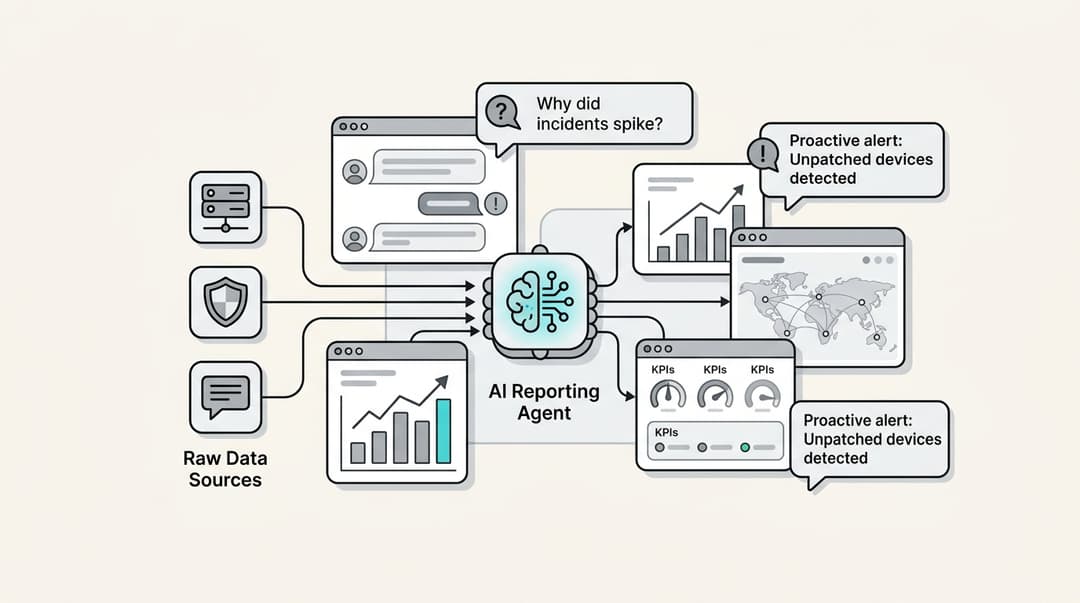
Wenn manuelle Annotation so mühsam ist, was ist die Alternative? Die gute Nachricht ist, dass Sie diesen langsamen, teuren und voreingenommenen Prozess nicht mehr durchlaufen müssen. Moderne KI-Plattformen sind darauf ausgelegt, direkt aus den Daten und dem Wissen zu lernen, das Sie bereits haben, und Ihre bestehende Helpdesk-Historie und internen Dokumente automatisch in eine Trainingsressource zu verwandeln.
Lassen Sie die KI aus Ihrer Geschichte lernen, um die manuelle KI-Annotation zu ersetzen
Anstatt ein Team zu bezahlen, um einen beschrifteten Datensatz von Grund auf zu erstellen, verbinden sich Plattformen wie eesel AI direkt mit Ihrem Helpdesk.
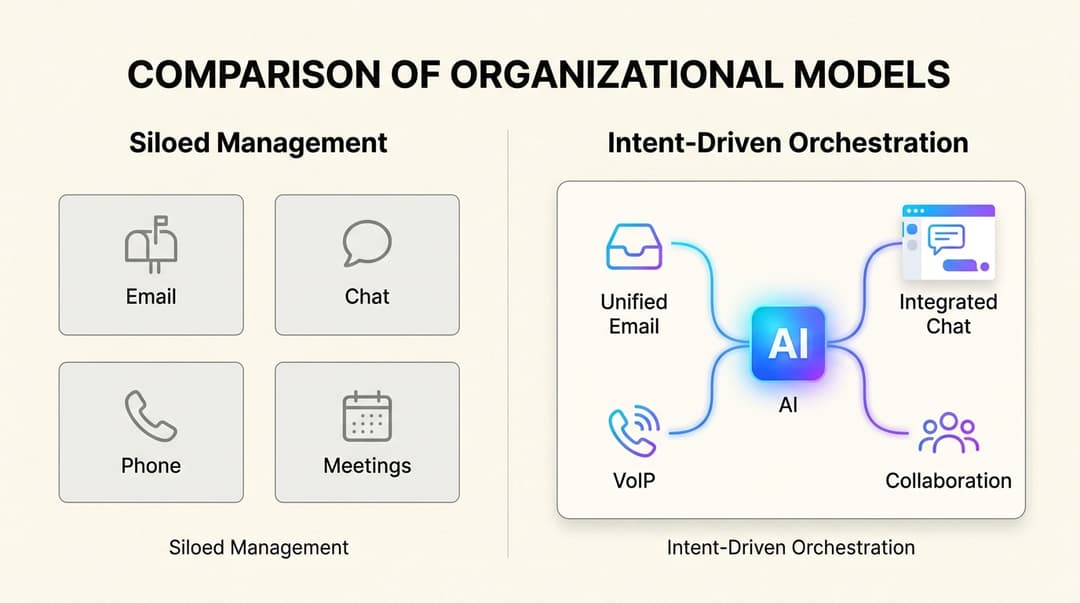
Der eesel AI KI-Agent durchforstet Tausende Ihrer vergangenen Support-Tickets von Helpdesks wie Zendesk, Freshdesk oder [Intercom]. Er erkennt automatisch den Ton Ihrer Marke, identifiziert die häufigsten Gründe, warum Kunden Sie kontaktieren, und lernt, wie eine gute Lösung aussieht, ohne dass Sie etwas kennzeichnen müssen. Es ist wie eine automatisierte Form der KI-Annotation, die die Arbeit Ihres eigenen Teams als perfektes Trainingshandbuch nutzt.
Vereinheitlichen Sie all Ihr unstrukturiertes Wissen für die KI-Annotation
Die Antworten, die Ihre Kunden suchen, befinden sich nicht nur in alten Tickets. Sie sind über interne Wikis, öffentliche Hilfedokumente und zufällige Dateien verstreut. Zu versuchen, jeden Absatz in jeder Confluence-Seite oder Google Doc manuell zu kennzeichnen, ist keine Option.
Deshalb verbindet sich eesel AI mit über 100 Quellen, zieht all diese Inhalte ein und macht sie selbstständig verständlich. Es liest Ihre internen Dokumentationen, Hilfeartikel und sogar relevante Slack-Konversationen, um ein vollständiges Bild Ihres Unternehmens zu erstellen. Die KI erstellt ihre eigene Wissenskarte, ohne dass ein Mensch sie bei jedem Schritt anleiten muss.
Von Monaten zu Minuten: Die Vorteile des automatisierten Lernens für die KI-Annotation
Der Wechsel von manueller Kennzeichnung zu dieser Art von automatisiertem Lernen bietet Ihnen einige große Vorteile:
- Geschwindigkeit: Sie können in Minuten loslegen. Die Self-Service-Einrichtung eines Tools wie eesel AI ist eine Welt entfernt von der monatelangen Zeitachse eines typischen Annotation-Projekts.
- Relevanz: Die KI wird auf Ihre einzigartigen Kundenkonversationen und internen Dokumente trainiert. Dies macht sie weitaus genauer und bewusster für Ihren Geschäftskontext als eine generische KI, die auf zufälligen Daten aus dem Internet trainiert wurde.
- Vertrauen: Bevor die KI jemals mit einem echten Kunden spricht, können Sie Simulationen in eesel AI durchführen, um zu sehen, wie sie Tausende Ihrer vergangenen Tickets behandelt hätte. Dies gibt Ihnen eine risikofreie Möglichkeit, ihre Leistung zu überprüfen, zu sehen, wie hoch Ihre Lösungsrate wäre, und Anpassungen vorzunehmen, bevor Sie live gehen.
Die richtige KI-Annotation-Strategie für Ihr Support-Team wählen
Die Wahl wird jeden Tag klarer. Während manuelle Annotation früher die einzige Möglichkeit war, ist sie heute oft ein großes und unnötiges Hindernis. Hier ist eine kurze Übersicht, wie die verschiedenen Ansätze im Vergleich stehen:
| Merkmal | Manuelle Annotation | Ausgelagerter Service | Automatisierte Plattform (eesel AI) |
|---|---|---|---|
| Zeit bis zum Start | Monate bis Jahre | Wochen bis Monate | Minuten bis Stunden |
| Kosten | Hoch (Gehälter, Gemeinkosten) | Sehr hoch (Servicegebühren) | Niedrig & vorhersehbar (SaaS-Abonnement) |
| Skalierbarkeit | Schlecht (manueller Aufwand) | Moderat (abhängig vom Anbieter) | Hervorragend (lernt automatisch) |
| Datenrelevanz | Gut, aber statisch | Gut, aber statisch | Höchste (lernt aus Ihren Live-Daten) |
| Einrichtungsaufwand | Extrem hoch | Hoch | Einfacher Self-Service |
Manuelle KI-Annotation stoppen, anfangen zu lösen
KI-Annotation ist ein wesentlicher Bestandteil beim Aufbau eines jeden KI-Systems, aber die Art und Weise, wie wir es erledigen, hat sich völlig verändert. Die Ära der riesigen, manuellen Datenkennzeichnungsprojekte verblasst und wird durch intelligente Plattformen ersetzt, die direkt aus dem Wissen lernen können, das Sie bereits haben.
Diese Veränderung beseitigt die größte und teuerste Hürde bei der Nutzung von KI. Sie ermöglicht es Support-Teams, sich wiederholende Aufgaben zu automatisieren, menschlichen Agenten mit Tools wie einem KI-Copilot einen Schub zu geben und bessere Kundenerfahrungen zu bieten, ohne den betrieblichen Albtraum eines traditionellen KI-Projekts. Die beste KI für Ihr Unternehmen ist eine, die Ihr Unternehmen tatsächlich versteht. Es ist an der Zeit, sich keine Sorgen mehr über die Kennzeichnung von Daten zu machen und diese Daten stattdessen zu nutzen, um Ihren Kunden zu helfen.
Bereit, in Minuten, nicht Monaten, einen leistungsstarken KI-Support-Agenten zu erstellen? eesel AI lernt automatisch aus Ihren vergangenen Tickets und Wissensdatenbanken, ohne dass eine manuelle Annotation erforderlich ist. Starten Sie noch heute Ihre kostenlose Testversion und sehen Sie, wie es funktioniert.
Häufig gestellte Fragen
Für die meisten Teams, ja. Moderne Plattformen, die direkt aus Ihrer Helpdesk-Historie und Wissensdokumenten lernen, sind erheblich schneller und kostengünstiger. Manuelles Labeling wird zu einem langsamen und unnötigen Schritt.
Es geht um Konsistenz und Skalierbarkeit. Ein automatisiertes System analysiert alle Ihre historischen Daten und erfolgreichen Lösungen auf einmal und vermeidet die menschliche Subjektivität und Fehler, die auftreten, wenn verschiedene Personen dieselben Daten unterschiedlich labeln.
Der häufigste Fehler ist die Unterschätzung von Zeit und Kosten. Teams nehmen oft an, dass es eine schnelle Aufgabe ist, aber es wird schnell zu einem monatelangen Projekt, das ständige Verwaltung und Qualitätskontrolle erfordert, was den eigentlichen KI-Start verzögert.
Im Großen und Ganzen, nein. Das System lernt kontinuierlich aus Ihren neuen Support-Tickets und aktualisierten Wissensdokumenten, sodass Sie kein statisches Datenset haben, das ständig neu gelabelt werden muss. Sie können sich darauf konzentrieren, Ihre Wissensdatenbank zu verbessern, anstatt Daten zu labeln.
Dies ist eine berechtigte Sorge. Allerdings kann die KI, indem sie aus Tausenden von Tickets lernt und Informationen mit offiziellen Wissensdokumenten abgleicht, die objektivsten und konsistentesten Muster identifizieren und sich auf diese verlassen, was hilft, die Auswirkungen voreingenommener Einzelinteraktionen zu reduzieren.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.