
We’ve all seen how powerful AI models like OpenAI’s GPT series can be. But if you’ve tried using them for real business tasks, you’ve probably noticed that getting consistently good results is trickier than it seems. It really all comes down to one thing: the quality of your input determines the quality of your output.
This is the whole idea behind "prompt engineering." It's the skill of crafting instructions that guide an AI to give you exactly what you need, time after time. While it’s an incredibly useful skill, diving into OpenAI prompt engineering can get pretty technical, pretty fast, especially for business teams that don't have developers on standby. This guide will walk you through the key ideas and show you a much simpler way to get it working for your support teams.
What is OpenAI prompt engineering?
What is prompt engineering, really? It's more than just asking a question. Think of it like giving a detailed brief to an incredibly smart assistant who takes everything you say very, very literally.
A good comparison is onboarding a new support agent. You wouldn't just tell them to "answer tickets" and then walk away. You’d give them a specific persona to adopt, a friendly yet professional tone of voice, access to your knowledge base, examples of what great responses look like, and clear rules on when to escalate a ticket. A well-engineered prompt does the same thing for an AI. It usually includes:
-
Clear instructions: What is the AI's role and what is its goal?
-
Context: What background information does it need to do the job?
-
Examples: What are a few samples of a good output?
-
A defined format: How should the final answer be structured?
Crafting these prompts by hand is one way to go about it, but as you'll see, it's not always the most practical path for busy teams.

Key techniques for effective OpenAI prompt engineering
Before we get into the specific techniques, it's helpful to think of these as the building blocks that make an AI genuinely useful. While developers often handle these things in code, the concepts themselves are useful for anyone trying to get better answers from an AI model.
Giving clear and specific instructions
AI models work best with specifics. If you give them vague instructions, you're going to get vague, unhelpful answers back. The more detail you provide about the role, the goal, and the format you want, the better your results will be.
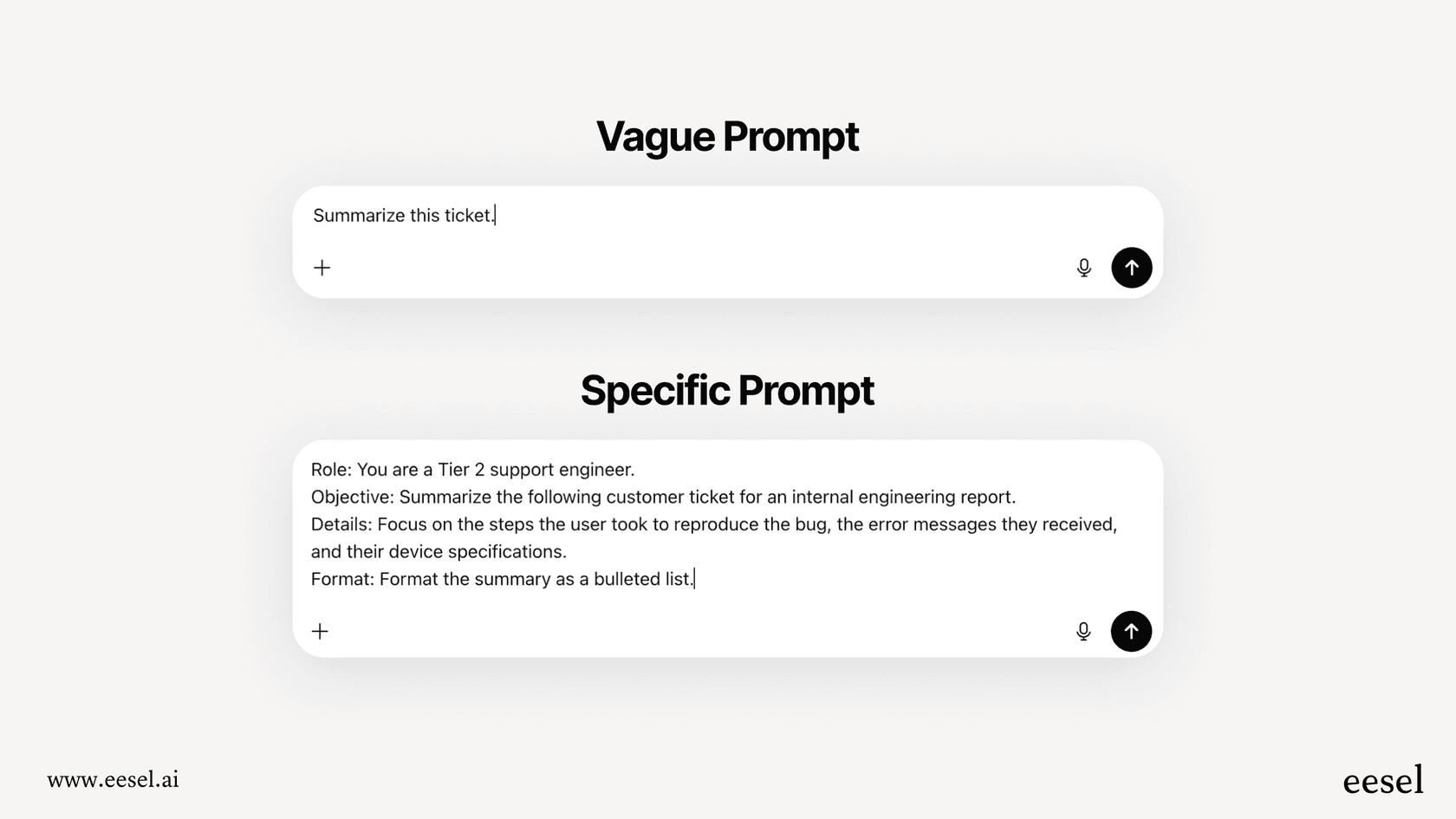
Here’s a quick example from a support context:
-
A not-so-great prompt: "Summarize this customer ticket."
-
A much better prompt: "You are a Tier 2 support engineer. Summarize the following customer ticket for an internal engineering report. Focus on the steps the user took to reproduce the bug, the error messages they received, and their device specifications. Format the summary as a bulleted list."
The second prompt gives the AI a persona ("Tier 2 support engineer"), a clear objective ("for an internal engineering report"), specific details to look for, and a required format. That level of detail makes the difference between a useless summary and a report someone can actually act on.
Providing examples to guide the model (few-shot learning)
"Few-shot learning" is a fancy term for a simple idea: you show the AI a few examples of what you want, and it learns the pattern. For instance, if you wanted an AI to classify the sentiment of a ticket, you could give it a few examples like this:
-
Ticket: "I can't believe how long this is taking to get resolved." -> Sentiment: Negative
-
Ticket: "Thanks a million, that worked perfectly!" -> Sentiment: Positive
The AI will pick up on the pattern and apply it to new tickets it hasn't seen before. The problem here is pretty obvious. Trying to manually create examples for every single type of support question, refunds, shipping, technical glitches, is a massive amount of work that just isn't practical for a growing team.
Instead of feeding an AI a few hand-picked examples, a tool like eesel AI can automatically learn from the thousands of past ticket resolutions your team has already written. It gets trained on your company's real-world context and brand voice from the get-go, no manual effort needed.

Supplying context to ground the AI (retrieval-augmented generation)
Retrieval-augmented generation (RAG) is like giving the AI an open-book test instead of making it answer from memory. You provide it with relevant documents, and it uses that information to put together its answer. This is a must-have for support teams. It's how you make sure the AI is giving answers based on your official help center articles, product docs, and internal wikis, not on some half-remembered data from two years ago.
The catch is that building a system to search all your different knowledge sources in real time is a major technical headache. You have to connect different APIs, manage the data, and keep it all synced up.
The best tools make this part easy. For example, eesel AI has one-click integrations with knowledge sources like Confluence, Google Docs, your help desk, and more. This brings all your knowledge together instantly, without any developer work.

The challenges of manual prompt engineering for support teams
While these techniques are powerful, trying to put them into practice manually creates some serious roadblocks for most customer support and IT teams.
Requires technical expertise and constant iteration
If you look at the official documentation from OpenAI, it’s clearly written for developers. It's filled with API references, code snippets, and technical settings. Crafting, testing, and tweaking prompts has become such a specialized skill that the "Prompt Engineer" has popped up as a new, in-demand job title.
For a support leader, that's a tough spot to be in. It means you're either hiring for a role you might not have budgeted for, or you're pulling your developers off the main product just to get the AI to work right.
Difficult to test and deploy with confidence
How do you know if a prompt that works for one ticket will work for the thousands of others you get each month? Deploying an untested, manually coded prompt to live customers is a big risk. A single poorly worded instruction could cause a flood of wrong answers, leading to frustrated customers and damage to your brand's reputation.
A proper testing environment isn't a "nice-to-have"; it's a necessity. This is why eesel AI includes a simulation mode. You can test your AI agent on thousands of your historical tickets in a safe environment, see exactly how it would have responded, and get an accurate idea of your automation rate before a single customer ever interacts with it. It’s about deploying with confidence, not just hoping for the best.

Unpredictable costs and performance
When you build a custom solution using the OpenAI API, you're looking at two kinds of costs: the developer time to build and maintain it, and the direct cost of using the API, which is usually based on how many "tokens" (pieces of words) you use.
This can lead to some wildly unpredictable bills. A sudden spike in customer tickets means a spike in your AI costs. You're essentially penalized for having a busy month. For businesses that need to stick to a budget, this can be a real problem. For instance, while ChatGPT has a free tier, any serious business use needs a paid plan, and the costs go up from there.
| Plan | Price (per user/month) | Key Features |
|---|---|---|
| Free | $0 | Access to GPT-5, web search, limited file uploads & analysis. |
| Plus | $20 | Everything in Free, plus extended model access, higher limits, and access to newer features like Sora. |
| Business | $25 (annual) or $30 (monthly) | Secure workspace, admin controls, data excluded from training, connectors to internal apps. |
This unpredictability is a big reason why teams often look for a platform with more predictable costs. For instance, eesel AI works on a flat-fee model. You know exactly what you're paying each month, so a busy support queue doesn't lead to a surprise bill.
The eesel AI approach: Prompt engineering made simple
The goal shouldn't be to turn support managers into developers. The best platforms take all the power of OpenAI prompt engineering and package it into a simple interface that anyone on a business team can use.
eesel AI was built to solve this exact problem. It handles the complicated technical work in the background, so you can focus on what you want the AI to do, not how to build it. Here’s how the manual, developer-heavy approach compares to the simple, self-serve eesel AI way:

| Manual Prompt Engineering | The eesel AI Way |
|---|---|
| You're stuck writing code or wrestling with API calls. | You use a simple editor to set the AI's persona, tone, and when it should escalate. |
| You have to manually create and update examples for the AI. | The AI learns directly from thousands of your team's past tickets. |
| Your engineers have to build a custom system to pull in context. | You connect your tools like Zendesk, Slack, and Notion with a few clicks. |
| Your developers need to code custom actions. | You set up actions, like looking up order info, from a no-code dashboard. |
| Testing involves writing scripts and complex evaluations. | You can simulate performance on past tickets with a single click to get actionable reports. |
Focus on results, not the process
OpenAI prompt engineering is the engine that drives high-quality AI responses, but you don't need to be a mechanic to drive the car.
If you're leading a support team, your goal is pretty straightforward: you want to lower resolution times, boost CSAT, and make your team more efficient. Your focus should be on those outcomes, not on the complicated and time-consuming process of engineering prompts from the ground up. Platforms like eesel AI give you all the power of advanced prompting through a simple, controllable interface that’s designed for your business needs, not a developer’s.
Ready to get the benefits of advanced AI without the technical headaches? Sign up for eesel AI, and you can have a fully functional AI agent learning from your data in minutes.
Frequently asked questions
What exactly is OpenAI prompt engineering and why should a business team care about it?
OpenAI prompt engineering is the art and science of crafting precise instructions for AI models to ensure they generate consistently high-quality, relevant outputs. For business teams, it's crucial because it directly influences the effectiveness and reliability of AI tools in real-world applications, ensuring the AI performs tasks exactly as needed.
Is learning OpenAI prompt engineering a necessary skill for everyone on a support team?
While understanding the concepts of OpenAI prompt engineering is beneficial, becoming an expert isn't necessary for every team member. Modern platforms are designed to abstract away the technical complexities, allowing support teams to leverage AI without needing specialized coding or prompt-crafting skills.
What are the core techniques involved in effective OpenAI prompt engineering?
Effective OpenAI prompt engineering typically involves providing clear and specific instructions, offering examples through "few-shot learning," and supplying relevant context using "retrieval-augmented generation" (RAG). These methods help guide the AI to understand the task and generate accurate responses based on your specific requirements.
What are the challenges of performing OpenAI prompt engineering manually for a growing support team?
Manually implementing OpenAI prompt engineering can be challenging due to its technical complexity, requiring specialized expertise and constant iteration. It's also difficult to test and deploy prompts with confidence at scale, and managing unpredictable costs associated with API usage can be a significant hurdle for budget-conscious teams.
How can I test if my OpenAI prompt engineering efforts will be effective before deploying to live customers?
To confidently deploy your AI, it's essential to test your OpenAI prompt engineering in a controlled environment. Tools with simulation modes allow you to run your AI agent against historical data, predicting its performance and automation rates before any customer interaction.
Does good OpenAI prompt engineering help manage the costs of using AI models?
While effective OpenAI prompt engineering can improve the efficiency of token usage, the underlying pay-per-token model of direct API use can still lead to unpredictable costs. Platforms offering flat-fee models provide more budget predictability, regardless of fluctuations in customer interactions.









