If you're building anything with AI, whether it's a customer support bot or an internal Q&A tool, you've probably had this thought: "What if someone says something... bad?"
It's a valid concern. Keeping your platform safe from harmful or inappropriate content isn't just a nice-to-have; it's essential for protecting your users and your brand.
This is exactly what the OpenAI Moderation API is for. It’s a handy tool that helps you spot and filter out a whole range of nasty stuff in both text and images. In this guide, we'll walk through everything you need to know about it, from its features and pricing to its real-world limitations. We'll also look at what it takes to go from just flagging content to building a full-blown moderation system that actually works.
What is the OpenAI Moderation API?
Think of the OpenAI Moderation API as a quick content safety check. You send it some text or an image, and it tells you if the content is potentially harmful by flagging it against OpenAI's usage policies.
It’s basically your first line of defense. The whole point is to catch problematic content early so you can decide what to do next, whether that's filtering a message, blocking a user, or sending it to a human for a closer look.
And maybe the best part? It’s completely free. That makes it a super accessible starting point for any developer looking to add a layer of safety to their app without worrying about costs.
Key features of the OpenAI Moderation API
The API has gotten a lot better since it first launched, and the latest models are more powerful and accurate than ever. Here are a few of the core features that stand out.
Multimodal classification for text and images
With the new "omni-moderation-latest" model, built on GPT-4o, the OpenAI Moderation API can now analyze both text and images in a single go. This is a huge deal for apps that deal with mixed media, like community forums or support chats where people are uploading screenshots.
Right now, this text-and-image feature works for three main categories:
-
Violence ("violence" and "violence/graphic")
-
Self-harm ("self-harm", "self-harm/intent", and "self-harm/instruction")
-
Sexual content ("sexual")
The other categories are still text-only for now, but it's a big step towards covering all your bases, no matter the content type.
Comprehensive content categories
The API doesn't just look for one type of bad content; it scans for a whole spectrum of issues. The newer models have even added more nuanced classifications. Here’s a quick rundown of what it can catch:
| Category | Description | Inputs |
|---|---|---|
| "harassment" | Language that expresses, incites, or promotes harassment. | Text only |
| "hate" | Content promoting hate based on race, gender, ethnicity, religion, etc. | Text only |
| "self-harm" | Anything that encourages or shows acts of self-harm like suicide or cutting. | Text & images |
| "sexual" | Content meant to be sexually exciting or that promotes sexual services. | Text & images |
| "violence" | Content showing death, violence, or serious physical injury. | Text & images |
| "illicit" | Content that gives instructions on how to do illegal things (e.g., "how to shoplift"). | Text only |
Improved accuracy and calibrated scores
The "omni-moderation-latest" model is also much more accurate, especially with languages other than English. OpenAI’s own tests showed it was 42% better on a multilingual test set than the previous version.
Another nice touch is that the model's scores are now "calibrated." In simple terms, this means the confidence score you get (a number from 0 to 1) is a more realistic reflection of the chances that the content is actually violating a policy. This lets you set your own filtering thresholds with a lot more confidence.
When you make a request, the API gives you back a JSON object with three important fields:
-
"flagged": A simple "true" or "false" telling you if anything was flagged at all.
-
"categories": A list of the specific categories that were flagged as "true".
-
"category_scores": The detailed confidence scores for every single category.
How to use the OpenAI Moderation API
While the API itself is powerful, getting it to work well in your app takes a bit of technical setup and planning. Here’s a quick look at what’s involved.
Getting started
First things first, you'll need an OpenAI account and an API key, which you can grab from your organization settings page. The good news is that unlike some other APIs, you get access to the moderation endpoint right away. No waiting required.
Making a moderation request
Once you have your key, you just need to send a POST request to the "/v1/moderations" endpoint. You really only need two things: the "input" (the text or image URL you want to check) and the "model" you want to use.
curl https://api.openai.com/v1/moderations \
-X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"input": "I want to kill them.",
"model": "omni-moderation-latest"
}'
The API will send back a JSON object with the results. For a quick check, you can just look at the "flagged" field to see if it's "true" or "false".
graph TD A[User Submits Content] --> B{Call OpenAI Moderation API}; B --> C{Content Flagged?}; C -- Yes --> D[Custom Workflow Logic]; D --> E[Block User]; D --> F[Escalate to Human]; D --> G[Send Warning]; C -- No --> H[Content Approved];
subgraph Challenges direction LR I((Latency)) J((Custom Rules)) K((Engineering Overhead)) end D --> I; D --> J; D --> K;
The challenges of building a full moderation workflow
Making the API call is easy. The hard part is what comes next. The OpenAI Moderation API tells you if content is harmful, but it doesn't tell you what to do about it. This leaves your team with a few hurdles to clear.
You have to build the workflow logic. You'll need to write all the code that decides what happens when content gets flagged. Should the user be blocked? Should the ticket be escalated to a human agent? Should an automated warning be sent? Every single one of these actions needs to be custom-built.
Latency can be an issue. Calling another API for every message can slow down your application. To keep the user experience snappy, you might need to build an asynchronous system that runs the moderation check in the background, which adds another layer of complexity.
Custom rules are on you. The API’s categories are set in stone. If you need to filter content based on your own brand guidelines (like avoiding political talk, refund requests, or mentions of competitors), you have to build a whole separate system for that. This usually means another LLM call, which adds more cost and engineering overhead.
OpenAI Moderation API pricing
This is the easy part. One of the best things about the OpenAI Moderation API is the price: it's free. According to OpenAI's official pricing page, the "omni-moderation" models don't cost anything to use.
This makes it a no-brainer for projects of any size, from tiny startups to big companies. While some folks in community forums think it's meant to be used alongside other paid OpenAI APIs, that covers pretty much everyone building in the OpenAI ecosystem anyway.
Beyond the OpenAI Moderation API: An integrated moderation and automation workflow
The free API is a fantastic starting point, but if you're running a real-world customer support operation, you need more than just a content flag. You need a system that connects that flag to an immediate, smart action. This is where a dedicated AI support platform really makes a difference.
Go from detection to resolution in minutes
With a DIY approach, you have to code every single step of the workflow yourself. A platform like eesel AI changes the game with pre-built logic and one-click helpdesk integrations for tools you already use, like Zendesk or Freshdesk.
Instead of just spotting a problem, you can act on it instantly. For example, you could set up an eesel AI agent to see a moderation flag, immediately stop its own reply, and automatically escalate the ticket to a human with an "urgent review" tag. You can build that entire workflow in a few minutes without touching a single line of code.
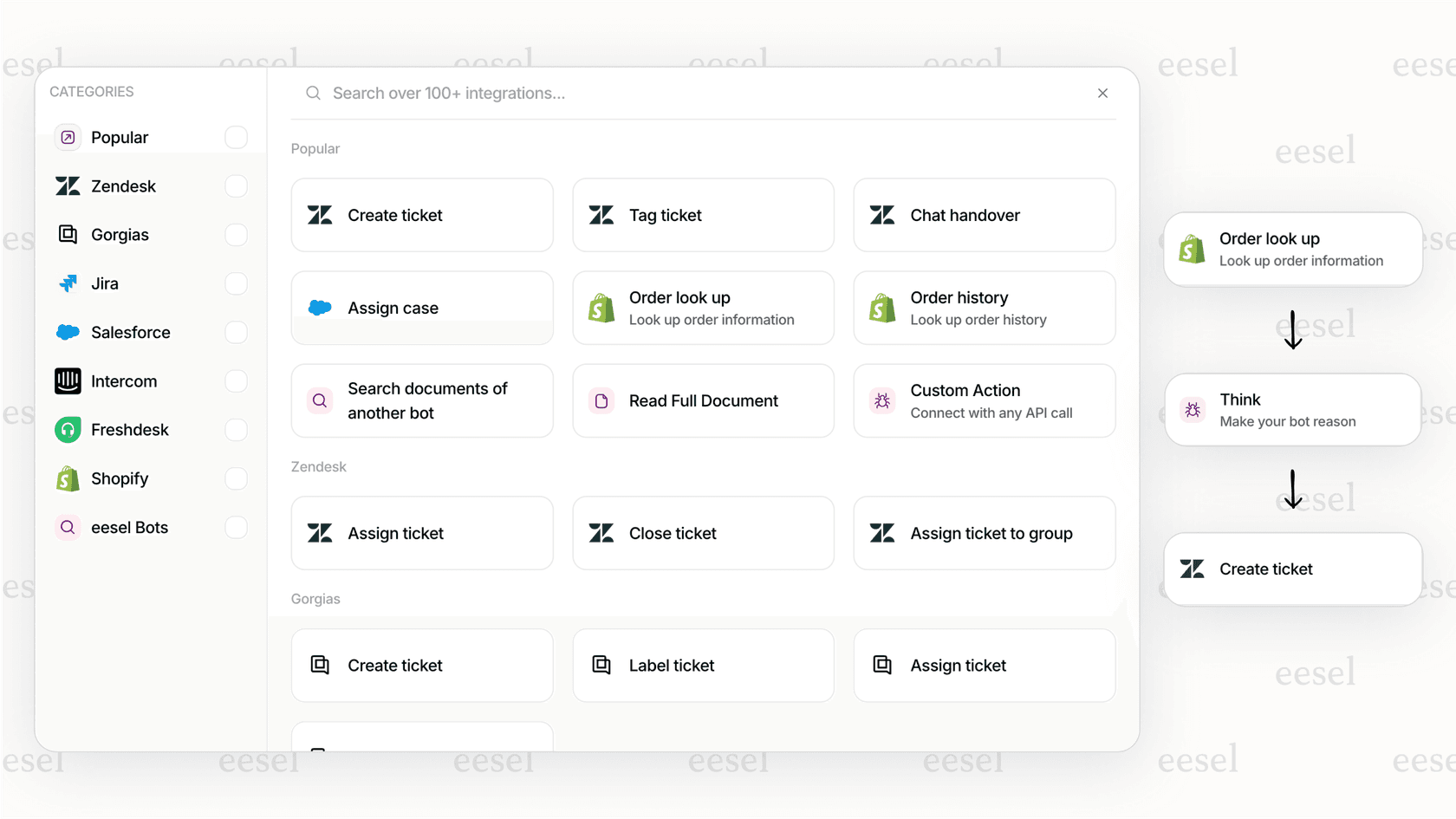
Combine content safety with custom business rules
The fixed categories of the OpenAI Moderation API can’t handle your brand-specific rules. An integrated platform solves this by giving you a fully customizable workflow engine. With eesel AI's prompt editor, you can define your AI's personality and layer in custom moderation rules that go way beyond the standard safety net.
An e-commerce brand, for instance, could use the standard moderation API to block harmful content, while also using eesel AI's custom instructions to stop the AI from making promises about shipping times or talking about competitors.
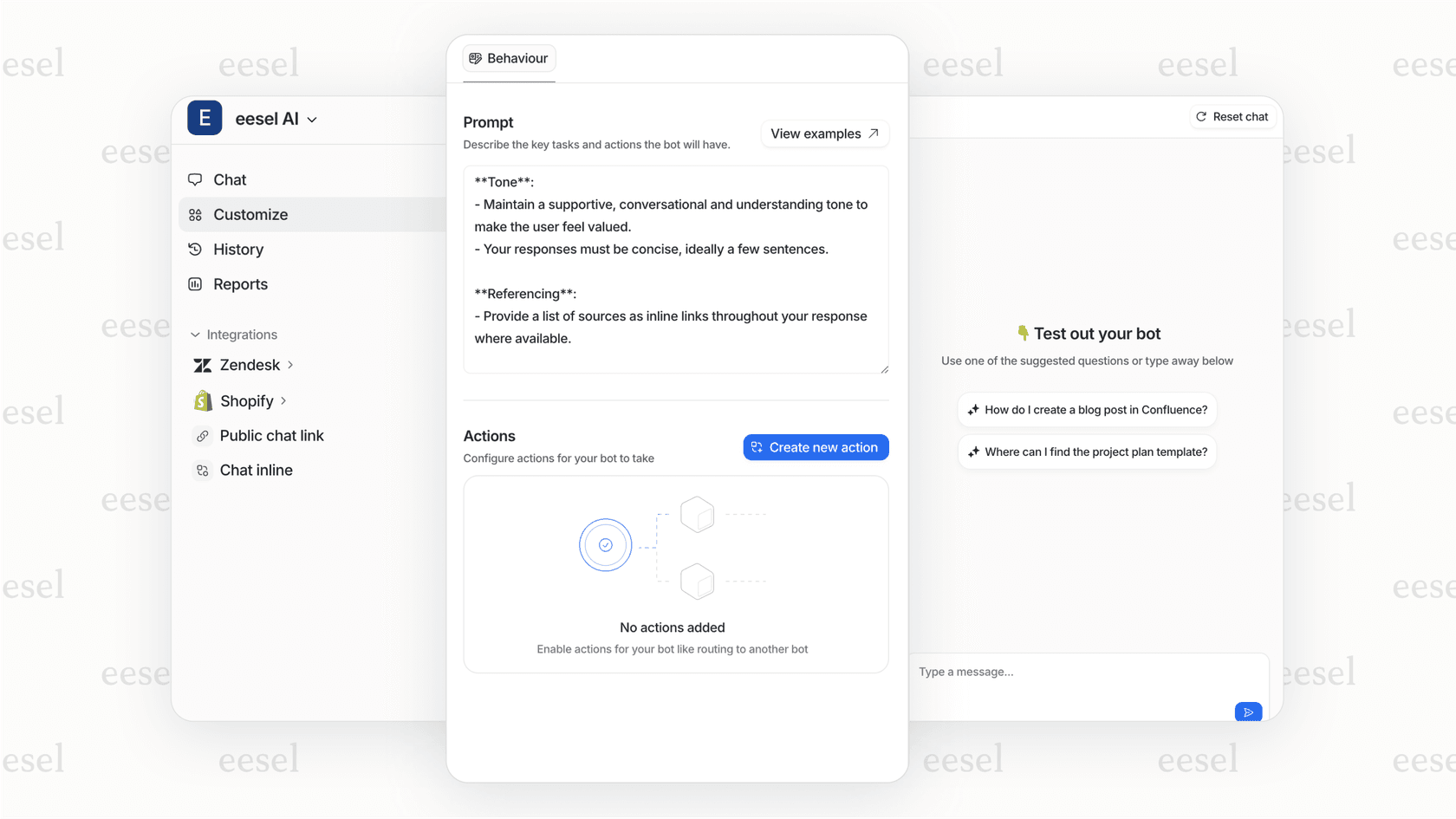
Simulate and deploy your workflow with confidence
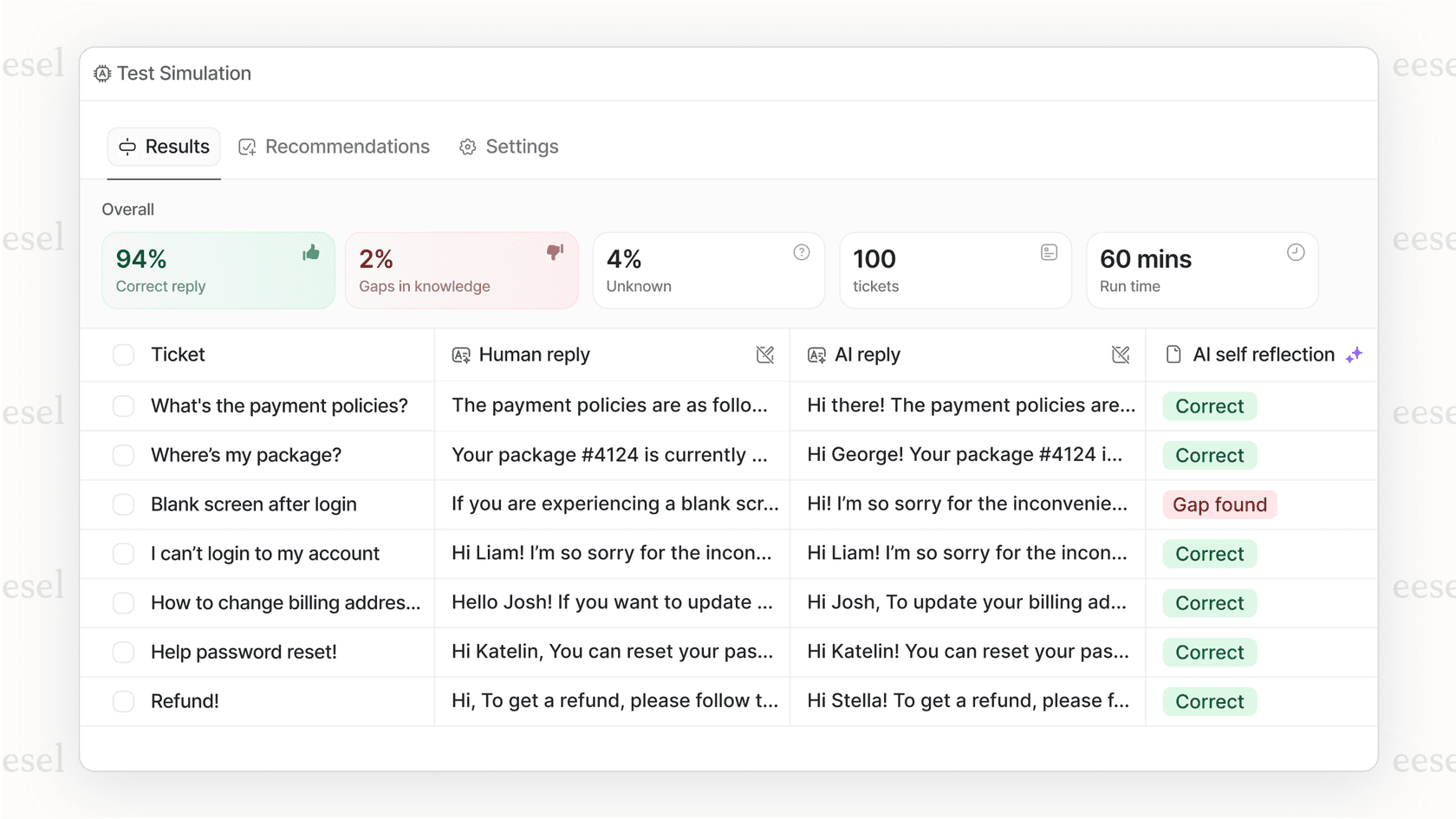
Rolling out a moderation system you built yourself can feel like a gamble. Are your thresholds too strict, leading to false alarms? Or are they too loose, letting bad content slip through?
eesel AI takes the guesswork out of it with a powerful simulation mode. Before you go live, you can run your entire automation and moderation setup against thousands of your past support tickets. This gives you a clear picture of how your AI will behave in the wild, so you can tweak your rules and deploy knowing it will work as expected.
Final thoughts on the OpenAI Moderation API
The OpenAI Moderation API is a fantastic tool. It’s free, powerful, and an excellent way to add a baseline of content safety to any application you're building. With its new multimodal model, it’s more useful than ever and should definitely be in your developer toolkit.
But flagging content is just the first step. The real work is turning that flag into a smooth, reliable, and customized business process. Building these workflows from scratch is a heavy lift that requires a lot of engineering time, ongoing maintenance, and careful testing.
For teams that need to move fast without cutting corners, an integrated platform like eesel AI offers the whole package. It bundles the power of OpenAI's moderation with a no-code workflow builder, deep integrations, and solid testing tools. It lets you go from simple detection to full automation in minutes, not months.
Build smarter, safer support workflows with eesel AI
Ready to build a support system that's not just safe, but also smart and efficient? Try eesel AI for free and see how easy it is to automate your support workflows in minutes.
Frequently asked questions
Is the OpenAI Moderation API completely free to use for any project?
Yes, according to OpenAI's official pricing, the "omni-moderation" models are completely free to use. This makes the OpenAI Moderation API a highly accessible tool for adding a baseline layer of content safety to applications of any size.
What types of harmful content can the OpenAI Moderation API detect in both text and images?
The "omni-moderation-latest" model can detect violence, self-harm, and sexual content in both text and images. Other categories like harassment, hate, and illicit content are currently supported for text inputs only.
Can the OpenAI Moderation API be used as a standalone solution for comprehensive content moderation?
While the OpenAI Moderation API is excellent for identifying harmful content, it primarily flags issues without providing workflow logic. For a complete moderation system that automates responses or escalations, it typically needs to be integrated with additional custom-built solutions or a dedicated AI support platform.
How accurate is the OpenAI Moderation API, especially for non-English content?
The "omni-moderation-latest" model boasts improved accuracy, including a 42% improvement on multilingual test sets compared to previous versions. Its calibrated scores also provide a more reliable indication of confidence for policy violations across different languages.
What's the initial setup required to start using the OpenAI Moderation API?
To get started, you'll need an OpenAI account and an API key from your organization settings. Once you have the key, you can send POST requests to the "/v1/moderations" endpoint with your content input and the desired model.
Does the OpenAI Moderation API allow for custom moderation rules tailored to specific business needs?
The OpenAI Moderation API provides predefined content categories. It does not natively support custom, brand-specific rules (e.g., blocking mentions of competitors or specific product policies). Integrating it with a platform offering a customizable workflow engine, like eesel AI, is necessary for such bespoke requirements.