
So, you’re thinking about using an LLM to help run your business. That's a great move. But there’s always that nagging question: how do you make sure it’s actually reliable and not just a ticking time bomb of weird answers? You can’t just flip a switch on a large language model (LLM) and cross your fingers.
If you don't test it properly, your AI could start giving out wrong information, adopting a bizarre tone that’s totally off-brand, or just failing to follow simple instructions. All of that adds up to a terrible customer experience. This is why having a solid way to test your AI isn't just a nice-to-have; it's essential.
To tackle this, OpenAI created a framework called OpenAI Evaluation. This guide will walk you through what it is, how the tech folks use it, and why it's probably not the right tool for most business teams. We'll also look at how platforms like eesel AI give you a much more straightforward path to deploying AI you can actually trust.
What is OpenAI Evaluation?
In simple terms, OpenAI Evaluation (or "Evals," as it's often called) is a toolkit for developers to create and run tests on language models. It’s how they check if the prompts they’re writing or the models they’re tweaking are actually doing what they're supposed to. Think of it as a quality check for your AI, making sure that when you update something, you don't accidentally break five other things.
There are two main flavors of these tests:
-
Code-based checks: These are for the black-and-white stuff. A developer can write a test to see if the model's output includes a specific word, is formatted in a certain way (like JSON), or correctly sorts something into a category. It's perfect for when there’s a clear right or wrong answer.
-
AI-graded checks: This is where things get a bit more interesting. You can use a really powerful AI (like GPT-4o) to judge the work of another AI. For example, you could ask it to rate how "friendly" or "helpful" a customer support reply is. It’s basically like having an AI supervisor review another AI's homework.
The whole point of using OpenAI Evals is to get hard numbers on how your AI is performing. This helps teams see if they're making progress and, more importantly, catch any slip-ups before they affect your customers. It’s a crucial practice for anyone building serious AI tools, but it’s also deeply technical.
How a standard OpenAI Evaluation works
Getting a standard OpenAI Evaluation up and running is a job for a developer. To give you a real sense of it, let’s walk through a common example from OpenAI’s own documentation: classifying IT support tickets.
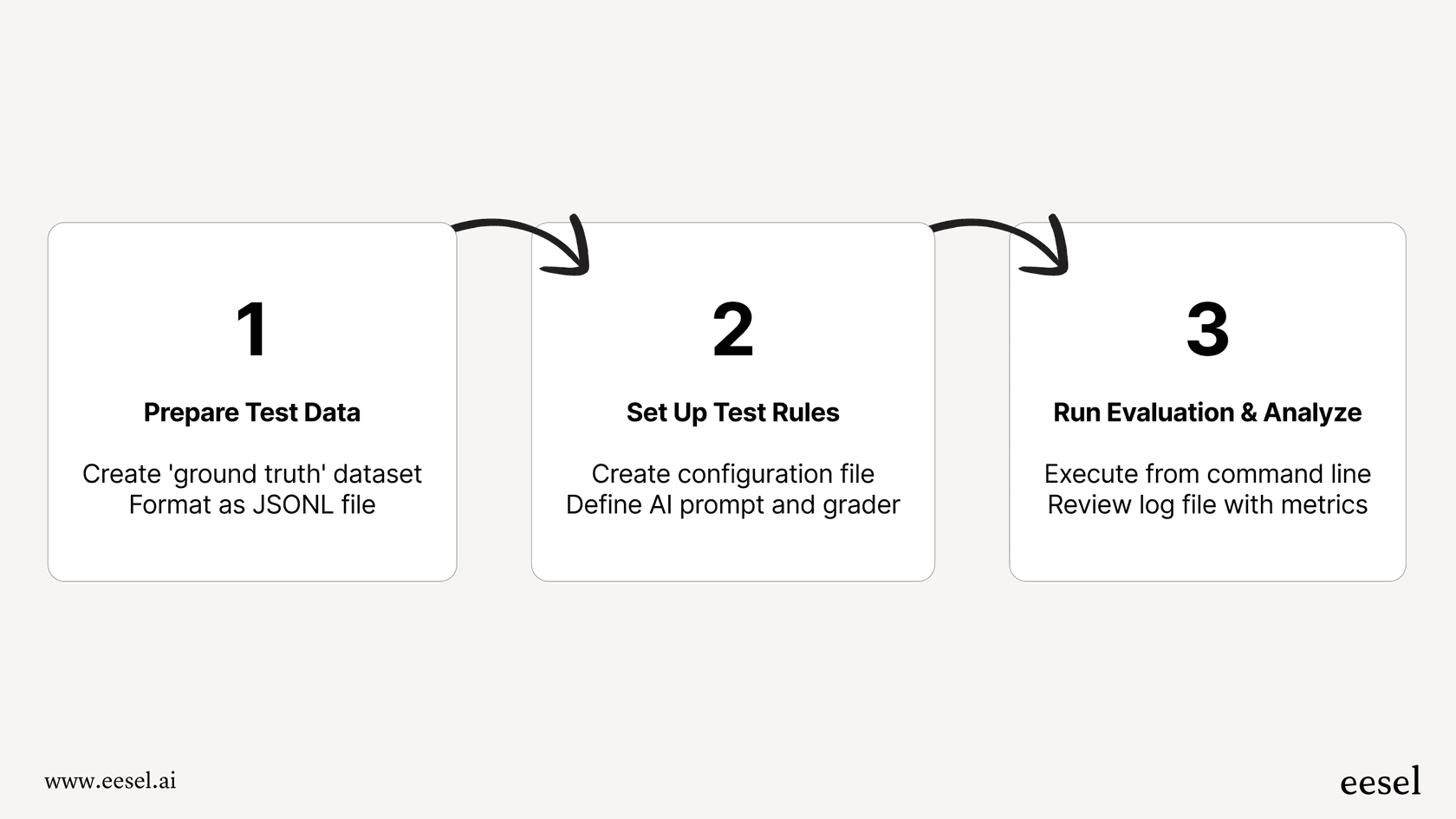
Step 1: Get your test data ready
First, you need what’s called a "ground truth" dataset. This is just a fancy term for an answer key. It's a file full of sample questions paired with the perfect answers. The catch? This file needs to be in a very specific format called "JSONL" (JSON Lines).
For our ticket-sorting example, a couple of lines in that file might look like this:
{ "item": { "ticket_text": "My monitor won't turn on!", "correct_label": "Hardware" } }
{ "item": { "ticket_text": "I'm in vim and I can't quit!", "correct_label": "Software" } }
Now, creating this file isn't a one-and-done thing. Someone has to manually create it, clean it up, and make sure it’s formatted perfectly. For a simple task, that might be fine. But if you're dealing with complex customer issues, building a good dataset can be a massive project all on its own.
Step 2: Set up the test rules
Next, a developer has to create a configuration file that tells the evaluation tool how to test the model. This file lays out the prompt that gets sent to the AI and the "grader" that will check the AI's response against your answer key.
For our ticket example, the test might use a simple grader that just checks if the AI’s output exactly matches the "correct_label" in the dataset. This step involves knowing your way around special codes and placeholders to pull data from the test file into the test itself.
Step 3: Run the evaluation and see what happened
Finally, the developer kicks off the evaluation from their command line. The system then goes through every item in your dataset, sends the prompt to the model, gets an answer back, and scores it.

The result is usually a log file, a wall of text filled with data and metrics like how many tests "passed", "failed", and the overall "accuracy". These numbers tell you what happened, but they don't give you much insight into why something failed without some serious digging. It's a powerful system, but it’s definitely not built for the average user.
Common reasons to use OpenAI Evaluation
Even though the setup is a bit of a headache, the reasons behind it are very practical. Proper testing is what turns a fun AI demo into a tool you can rely on for your business.
-
Keeping it factual: This is a big one. You need to make sure your AI is giving correct information based on your knowledge base, whether that’s about product details or your return policy. An eval can check if the AI's answers actually match your official documents.
-
Following instructions: Many AI workflows need the output to be structured in a specific way. Evals can confirm that your AI can do things like generate clean JSON for another system to use or tag a support ticket with the right category from your list.
-
Getting the tone right: A support answer can be 100% correct but still sound robotic and cold. AI-graded evals can help you check if the AI’s tone matches your brand voice. You can ask the grader, "Does this reply sound empathetic and professional?" to keep the customer experience consistent.
-
Staying safe and fair: On a larger scale, developers use these same methods to test for safety issues. Evals help make sure models aren’t generating harmful, biased, or inappropriate content, which is obviously critical for any responsible AI tool.
The limits of OpenAI Evaluation for businesses
OpenAI Evaluation is a fantastic tool for the developers who are building AI. But for the business teams who have to manage that AI every day, it comes with some pretty big downsides.
Why OpenAI Evaluation is for developers, not your support team
The whole process, from making "JSONL" files to reading log data, is complicated and requires coding skills. You need engineers to set it up and keep it running. That’s a huge barrier for the support managers or IT leads who are actually in charge of the AI's performance. They need to know if the AI is doing its job, but you can’t expect them to learn to code just to find out.
What support teams actually need: Instead of a tool that lives in the command line, business teams need something designed for them. For instance, eesel AI has a simulation mode that lets you test your AI on thousands of your real, historical support tickets in just a few clicks. No code, no fuss. You get simple, visual reports showing you what you can expect to automate and can see exactly how the AI would have replied.

Why creating test data by hand is a dead end
Building and updating a good test dataset is a never-ending chore. Your customers’ problems are always changing as you launch new products or change your policies. A static test file you made in January will be hopelessly out of date by March, which makes your tests pretty meaningless.
A better approach: Your AI should learn from reality, not a file someone made months ago. eesel AI plugs right into your help desk (like Zendesk or Freshdesk) and your knowledge sources. It trains and tests on your actual past tickets and help center articles from the very beginning. Your test dataset is your real, live data, so your tests are always relevant without any extra work.

Why just testing text isn't the full picture
A standard OpenAI Evaluation is great for checking if a text reply is correct. But in a real support situation, the words are just one piece of the puzzle. A great AI agent doesn't just answer a question; it does something. The standard eval can't tell you if the AI successfully did things like tagging a ticket as urgent, escalating it to a person, or looking up an order status in Shopify.
Test the whole workflow: You need to test the entire process, not just the words. With the customizable workflow engine in eesel AI, you can build and test these actions right inside the simulation. You can see not only what the AI would have said, but also what it would have done. This gives you a complete picture of its performance so you can feel good about automating entire processes, not just text snippets.

Understanding the API pricing for OpenAI Evaluation
While the OpenAI Evals framework is open-source, running the tests will cost you. Every test you run uses API tokens, and that adds up on your bill. You pay for every prompt you send to the model you're testing and for every answer it generates. This is especially true when you use AI-graded evals, since you're paying for a second, more powerful model to do the grading.
Here’s a quick look at the pay-as-you-go costs for some of OpenAI's models:
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| "gpt-4o-mini" | $0.15 | $0.60 |
| "gpt-4o" | $5.00 | $15.00 |
| "gpt-5-mini" | $0.25 | $2.00 |
| "gpt-5" | $1.25 | $10.00 |
Pricing can change, so it's always a good idea to check the official OpenAI pricing page for the latest details.
A more predictable way: This token-based pricing can lead to some unpleasant surprises on your monthly bill, especially if you're running a lot of tests. In contrast, eesel AI offers predictable pricing. Plans are based on a set number of AI interactions per month, and all the testing you do in simulation mode is included. This makes budgeting for your AI tools much simpler, with no hidden costs for making sure your AI is ready to go.

Move beyond OpenAI Evaluation and start automating
OpenAI Evaluation is a big deal for developers building with LLMs. It proves that serious, methodical testing isn't just an extra step, it's at the core of building AI responsibly. However, because it's so technical and developer-focused, it’s just not practical for most business teams who need to manage AI for things like customer support or internal help desks.
The future of AI in business isn't just about raw power; it's about making that power safe, reliable, and easy for anyone to manage. That means you need testing tools that are built into your platform, easy to use, and designed for the people who will be using them every single day.
Instead of spending months trying to build a complex, code-heavy testing system, you can get all the benefits in just a few minutes. Sign up for eesel AI and run a free simulation on your own data. You'll see exactly what you can automate and can launch your AI agents feeling completely confident.
Frequently asked questions
What is OpenAI Evaluation and what is its primary purpose?
OpenAI Evaluation, often called Evals, is a toolkit designed for developers to create and run tests on language models. Its primary purpose is to quality-check AI models, ensuring they perform as expected and identifying any regressions during updates.
Why is OpenAI Evaluation considered more suitable for developers than for business teams?
The entire OpenAI Evaluation process, from creating specific "JSONL" files to interpreting complex log data, requires coding skills and technical expertise. This makes it challenging for non-technical business teams, like support managers, to set up, run, and manage effectively.
How does a standard OpenAI Evaluation work in practice, from data setup to analysis?
First, a developer prepares a "ground truth" dataset of questions and correct answers in "JSONL" format. Next, they create a configuration file defining the AI prompt and the grader rules. Finally, the evaluation is run from the command line, generating log files with performance metrics like accuracy.
What are the main limitations of using OpenAI Evaluation for businesses, particularly regarding test data?
A significant limitation is the need to manually create and constantly update test datasets, which quickly become outdated as business needs change. This makes maintaining relevant and comprehensive tests a continuous, resource-intensive task for businesses.
Are there direct costs associated with running an OpenAI Evaluation, and how is pricing structured?
Yes, running tests with OpenAI Evaluation incurs costs because it uses API tokens for every prompt sent and answer generated by the models. Pricing is typically pay-as-you-go, based on the number of input and output tokens, which can lead to unpredictable monthly bills.
Can OpenAI Evaluation test beyond just text output, such as entire AI-driven workflows with actions?
Standard OpenAI Evaluation is excellent for checking text replies but doesn't inherently test a complete workflow or actions an AI might take, like tagging tickets or looking up order statuses. It primarily focuses on the correctness of verbal or textual responses.



