There’s a lot of buzz around OpenAI's Realtime API, and honestly, it makes sense. The idea of building super-responsive, human-like voice agents is pretty exciting. The model that gets most of the attention is "gpt-4o-mini-realtime", mostly because it promises solid performance at what looks like a rock-bottom price.
But here’s the thing. As soon as you check the pricing page, you’re hit with jargon like "per million tokens" for text, audio, and something called cached inputs. It leaves most of us scratching our heads and asking the same question: "Okay, but what does that actually cost me per minute?"
If you're trying to figure out if a project is viable or just trying to set a budget, token-based pricing is a real pain. So, we decided to do the math for you. This guide breaks down the true cost of using the GPT realtime mini, uncovering the sneaky factors that can make your expenses balloon when you least expect it.
Understanding the OpenAI Realtime API
Before we jump into the numbers, let's get on the same page. The OpenAI Realtime API is a tool for developers who want to build apps with fast, speech-to-speech conversations. Basically, it lets you create an AI that can listen and talk back almost instantly, without the awkward lag you get with older technology.
It’s built for powering voice agents. Think of an AI that can handle customer service calls, book appointments, or answer internal questions for your team, all while sounding natural.
The API gives you a couple of models to work with. There’s the powerful "gpt-4o-realtime" for more complicated chats, and its cheaper, faster sibling, "gpt-4o-mini-realtime". We’re focusing on the mini version here because its low sticker price makes it the go-to starting point for many people.
The problem with OpenAI's token-based pricing
OpenAI charges you for every "token" your app uses. A token is just a tiny piece of data, it could be a word, a syllable, or a bit of audio. The cost is based on how many tokens you send to the model (input) and how many it sends back to you (output).
Here’s the official GPT realtime mini pricing from OpenAI's pricing page:
| Model & Token Type | Input Price (per 1M tokens) | Output Price (per 1M tokens) |
|---|---|---|
| gpt-4o-mini-realtime-preview | ||
| Text | $0.60 | $2.40 |
| Audio | $10.00 | $20.00 |
| Cached Audio Input | $0.30 | N/A |
These numbers look tiny, right? But this model makes it incredibly difficult to forecast your costs for a few reasons:
-
Call lengths are all over the place. A quick one-minute chat uses way fewer tokens than a complex ten-minute support call. How can you possibly predict the average?
-
The input-to-output ratio changes. A chatty customer and a quiet AI will cost less than a quiet customer who needs long, detailed explanations from the AI.
-
System Prompts: The Hidden Cost. This is the big one. To make a voice agent do anything useful, you have to give it instructions. This "system prompt" tells the AI who it is, what its job is, and how to act. This entire block of text gets sent as input tokens with every single back-and-forth in the conversation. A detailed prompt can easily double or triple your costs, and you might not even notice until the bill arrives.
-
It’s a mix of audio and text. The API is constantly juggling audio tokens (what the user says) and text tokens (what the AI processes and says back), and each has its own price tag. This mix turns simple cost estimation into a guessing game.
A practical cost-per-minute breakdown
To get past the theory, we ran some tests to see what these token costs actually look like in dollars per minute. We used the OpenAI Playground to simulate conversations, since it gives you real-time cost data.
We compared both the "gpt-4o-mini-realtime" and the beefier "gpt-4o-realtime" models. For each one, we tested a basic chat and then another one with a 1,000-word system prompt, a realistic setup for any business that needs its AI to know about products or follow a script.
The results were pretty surprising.
| Model & Configuration | Average Cost per Minute | Why it Matters |
|---|---|---|
| GPT-4o mini (No System Prompt) | ~$0.16 | Seems cheap, but an AI with zero instructions isn't useful for a business. |
| GPT-4o mini (With 1,000-word System Prompt) | ~$0.33 | The cost more than doubles just by giving the AI a basic instruction manual. |
| GPT-4o (No System Prompt) | ~$0.18 | A bit pricier but handles complex, multi-step conversations better. |
| GPT-4o (With 1,000-word System Prompt) | ~$1.63 | The cost jumps by over 800%. This is exactly how budgets get destroyed. |
The main takeaway here is that the advertised GPT realtime mini pricing is just the starting line. Your real cost is almost entirely driven by how you configure your agent. That system prompt, which you absolutely need for any business use case, is the single biggest thing that jacks up your bill. This volatility makes it tough to budget for and scale a voice AI project.
Beyond API fees: The other costs of building a voice AI agent
The API bill is just one part of the equation. If you're planning to build a voice agent from the ground up with the Realtime API, the real costs are buried in the engineering hours it takes to get it ready for customers.
How prompt engineering affects your costs
Getting an AI to follow instructions reliably is harder than it looks. Writing a good system prompt involves a lot of trial and error. A sloppy prompt leads to a confused AI, which leads to frustrated customers and money down the drain.
And it's not just the prompt. You have to feed the AI the right information. That means building a system to connect it to your help center articles, internal wikis, and product docs. This is a big engineering lift that requires setting up data pipelines and retrieval systems.
This is where a tool like eesel AI comes in handy. It gives you a straightforward prompt editor and automatically connects to your knowledge sources. You can link your Zendesk, Confluence, or Google Docs in just a few clicks, no coding required.

Integration costs
A voice agent that can't actually do anything isn't much help. To be useful, it has to connect to your other business systems. It needs to be able to create a ticket in your helpdesk, check an order status in Shopify, or hand off a conversation to a human in Slack.
Building these integrations yourself means custom code, managing API keys, and handling authentication for every single tool. It’s a ton of work, and you have to maintain it forever. In contrast, eesel AI has one-click integrations with dozens of common business tools, letting your agent take action from day one without you writing any code.
The risk of launching without proper testing: A hidden cost
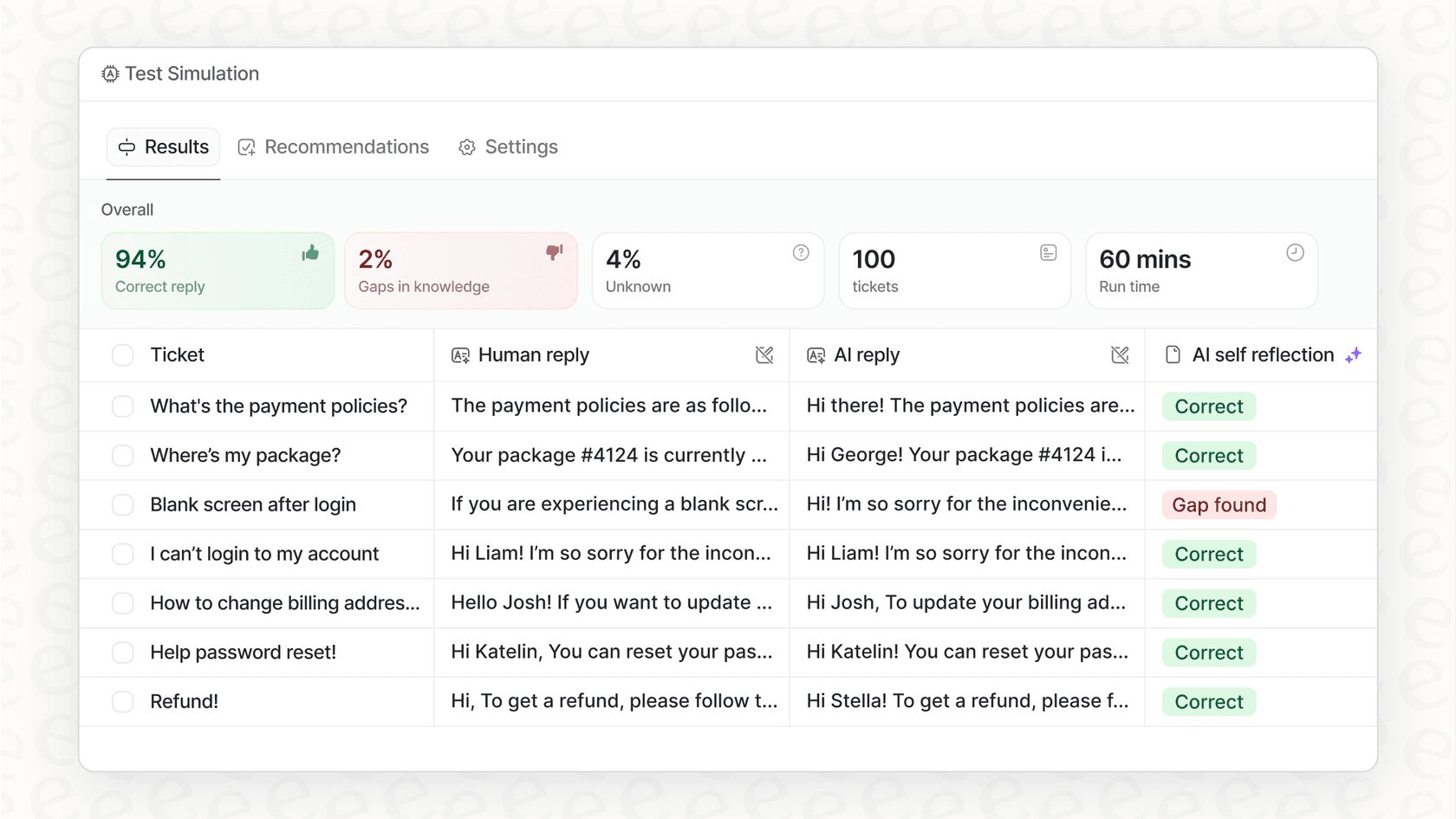
How do you know your agent is ready for prime time before you let it talk to actual customers? If you're building it yourself, the honest answer is often: you don't.
Setting up a proper testing environment to simulate real conversations at scale is a huge project on its own. But you really don't want to unleash an untested AI on your customer base. It's a massive risk to your reputation.
The AI agent from eesel AI helps solve this with a simulation mode. You can test your agent against thousands of your past support conversations to see exactly how it would have handled them. This gives you a clear, data-driven look at how it will perform and what your return on investment could be, so you can go live without crossing your fingers.
A smarter alternative: Predictable costs and faster deployment
Instead of wrestling with tokens and building everything from scratch, using an all-in-one AI platform is a much better path for most teams. It’s not just cheaper in the long run; it’s also way faster.
Go live in an afternoon
A custom voice agent can take a team of engineers weeks or even months to build. With eesel AI, you can be up and running on your own in a few hours. The whole platform is built to be self-serve. You can connect your knowledge, set up your agent's personality and rules, and run simulations without ever having to schedule a demo.
Get control with predictable, transparent pricing
The biggest problem with using the API directly is that you never know what your bill will be. One busy week could result in a surprisingly high invoice. eesel AI offers transparent plans based on a flat number of monthly AI interactions. You know exactly what you're paying every month, so there are no nasty surprises.
Plus, you get fine-grained control. You can set up rules that define exactly which questions the AI handles and which get sent straight to a human. This lets you start small by automating the easy, repetitive stuff first, and then scale up confidently as you go, all while keeping your costs in check.

From confusing pricing to clear business value
While the raw GPT realtime mini pricing looks cheap on the surface, the reality of token-based billing is a rollercoaster of unpredictable costs. On top of that, the API fees are just a small slice of the true cost of building a voice agent. The real investment is the mountain of engineering work needed for prompt tuning, integrations, and testing.
A platform like eesel AI offers a much saner approach. It uses powerful models like GPT-4o mini but handles all the complexity for you. By offering a self-serve platform with one-click integrations, powerful testing, and predictable pricing, eesel AI gives you a faster, safer, and more affordable way to launch AI agents that actually help your business.
Ready to see how simple it can be? Stop worrying about tokens and start automating. Try eesel AI for free and get your first agent live in minutes.
Frequently asked questions
Why is understanding GPT realtime mini pricing difficult with token-based billing?
Token-based billing makes it hard to predict costs because variables like call lengths, input-to-output ratios, and the constant inclusion of system prompts fluctuate significantly. These factors combine to make forecasting your expenses a substantial challenge.
How significantly does a system prompt affect GPT realtime mini pricing?
System prompts can drastically increase costs because they are sent as input tokens with every turn of a conversation. Our tests showed that a detailed 1,000-word prompt can more than double the per-minute cost compared to an agent with no instructions.
What's a realistic average cost per minute for GPT realtime mini pricing, considering a standard business setup?
Our practical breakdown found that with a necessary 1,000-word system prompt, the average cost for GPT-4o mini can be around $0.33 per minute. While a no-prompt scenario is cheaper at ~$0.16, it doesn't represent a useful business application.
Is there an alternative to direct API usage that offers more predictable GPT realtime mini pricing?
Yes, all-in-one AI platforms like eesel AI offer transparent, predictable pricing plans, typically based on a flat number of monthly AI interactions. This approach eliminates the volatility of token-based billing, allowing for better budget management and no surprising invoices.
How can using a platform help reduce the time and effort associated with managing GPT realtime mini pricing and deployment?
Platforms such as eesel AI drastically cut down deployment time and effort through self-serve setup, one-click integrations, and built-in testing features. This allows teams to get agents live in hours rather than weeks or months of custom development, simplifying cost management and operations.