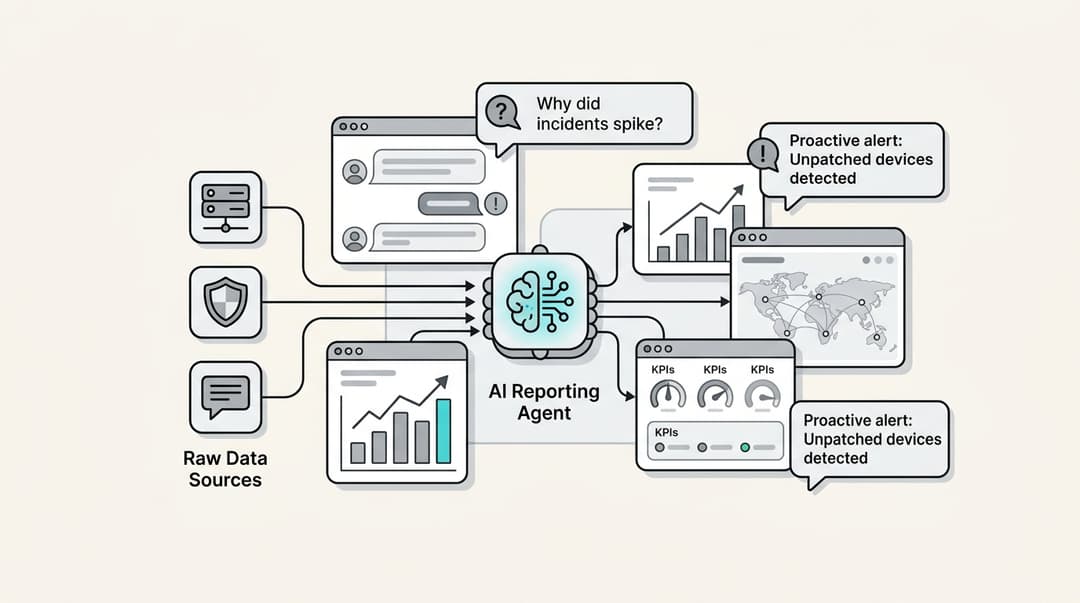
We all know that an AI is only as smart as the data it learns from. But how does an AI actually learn to understand a customer's problem, figure out if they're happy or furious, or know which help article to suggest? The secret ingredient has always been a process called AI annotation.
Simply put, AI annotation is the job of labeling data, like text from a support ticket or an image, so that machine learning models can make sense of it. Think of it as creating little sticky notes for a computer to teach it what's what. While it’s the bedrock of building smart AI, the old-school way of doing it is painfully slow, expensive, and a major headache for any team that just wants to get an AI support agent up and running.
This guide will walk you through what AI annotation is all about, the main types you'll see in support, and the problems with the traditional, manual approach. Most importantly, we'll show you how modern AI tools are making that whole process a thing of the past, letting you launch a powerful AI without a massive, time-sucking labeling project.
What AI annotation is (and why it matters)
You’ve probably heard the phrase "garbage in, garbage out." When it comes to machine learning, that’s not just a saying; it’s the golden rule. An AI model's performance is completely dependent on the quality of its training data. If you feed an AI messy, incorrect, or incomplete information, you're going to get messy, incorrect, and incomplete results. It's that simple.
AI annotation is the step that turns a mountain of raw, unstructured data into a clean, organized dataset that a machine can actually learn from. It’s about adding the context and meaning that machines can't figure out on their own.
It's a lot like training a new support agent. You wouldn't just give them a login and a huge pile of old tickets and say, "Good luck!" You'd sit with them, walk through real examples, and point out the important bits: "See this? That's an order number," "This customer is clearly frustrated," or "They're asking for a refund here." AI annotation does the exact same thing for a machine, just on a much bigger scale. For an AI in customer support, this is how it learns to categorize a ticket, understand a customer's tone, and find the real problem hidden in a long, rambling email.
Common types of AI annotation (with a focus on support)
While you can annotate just about any kind of data, there are a few types that are especially important for building smart support systems. Getting a handle on these helps make it clear how an AI learns to deal with customer conversations.
Text AI annotation: The language of your customers
For any kind of chatbot or helpdesk automation, text annotation is king. It's all about teaching a machine to pick up on the subtleties of how people talk and write. Here are the main flavors you'll come across:
- Intent recognition: This is all about figuring out what the customer actually wants. A human agent knows right away that "my password isn't working," "I can't log in," and "I forgot my credentials" are all the same problem. Intent recognition is the process of labeling all those different phrases with a single intent, like "Password Reset." This is the core skill that lets an AI route tickets to the right person or kick off the right automated workflow.
- Sentiment analysis: This involves tagging the emotion in a message as positive, negative, or neutral. An AI needs to be taught that "Thanks, that fixed it!" is good, while "I've been waiting for three days for a reply!" is very, very bad. Labeling for sentiment helps AI agents prioritize tickets from upset customers or even tweak their own tone in response.
- Named entity recognition (NER): This is just a fancy term for teaching an AI to spot and tag key pieces of information in a block of text. Think of it as finding the important nouns: names, order numbers, product names, locations, or dates. When a customer writes, "My order #12345 hasn't arrived at my address in Austin," NER is what lets the AI pull out "#12345" and "Austin" as separate, useful bits of data it can use to look up an order.
Other relevant AI annotation types
While text is the main event in the support world, a couple of other types play a useful supporting role:
- Image & video annotation: This is useful when customers send screenshots of an error message or a photo of a broken product. The annotation might involve drawing boxes around specific items in the image or simply classifying the whole thing (e.g., "damaged item," "UI bug").
- Audio annotation: This is mostly about transcribing phone calls or voicemails into text. Once that audio is turned into words, you can use all the text annotation methods we just talked about to figure out the customer's intent, sentiment, and other key details.
The hidden challenges of traditional AI annotation
Even though the idea of labeling data sounds simple enough, doing it manually is a huge roadblock for most companies. It's one of the biggest reasons so many AI projects either fail to launch or take way longer than anyone expected.
AI annotation takes forever and costs a fortune
Putting together a high-quality, annotated dataset is a massive undertaking. The process usually means hiring and managing teams of people to manually read and label thousands (or even hundreds of thousands) of customer tickets or messages. There are entire companies built around providing this kind of workforce. This manual grind can drag on for months and cost a small fortune before you even start training your first AI model.
AI annotation quality control is a constant headache
People are subjective. One person might label a customer's message as an "Urgent Feature Request," while someone else sees it as "General Feedback." Trying to get a large team to be perfectly consistent is nearly impossible. This inconsistency leads to endless review cycles and ridiculously long instruction manuals just to try and get everyone on the same page, which slows the whole process down even more.
Manual AI annotation doesn't keep up with your business
Your business is always changing. You launch new features, update policies, and customers find new ways to ask for things. Every time something shifts, your training data becomes a little more obsolete. With manual annotation, you either have to go back and re-label huge chunks of data or start a whole new project from scratch. It creates a permanent bottleneck that stops your AI from evolving with your business.
Human bias in AI annotation can create a flawed AI
Whether we intend to or not, human annotators can inject their own biases into the data labels. If the training data reflects unconscious assumptions about certain types of customers or consistently downplays certain issues, the AI will learn those same biases. This can lead to an AI that gives unfair or inconsistent answers, creating a bad experience for your customers.
The modern AI annotation approach: How to get powerful AI without manual annotation
So if manual annotation is such a pain, what's the alternative? The good news is that you don't have to go through that slow, expensive, and biased process anymore. Modern AI platforms are built to learn directly from the data and knowledge you already have, turning your existing helpdesk history and internal docs into a training resource automatically.
Let the AI learn from your history to replace manual AI annotation
Instead of paying a team to build a labeled dataset from scratch, platforms like eesel AI connect straight to your helpdesk.
The eesel AI AI Agent digs through thousands of your past support tickets from helpdesks like Zendesk, Freshdesk, or Intercom. It automatically figures out your brand's tone of voice, identifies the most common reasons customers contact you, and learns what a good resolution looks like, all without you having to label a single thing. It’s like an automated form of AI annotation that uses your own team's work as the perfect training manual.
Unify all your unstructured knowledge for AI annotation
The answers your customers are looking for aren't just in old tickets. They're scattered across internal wikis, public help docs, and random files. Trying to manually tag every paragraph in every Confluence page or Google Doc is a non-starter.
That’s why eesel AI connects with over 100 sources, pulling in and making sense of all that content on its own. It reads your internal documentation, help center articles, and even relevant Slack conversations to build a complete picture of your business. The AI creates its own map of your knowledge without needing a human to guide it every step of the way.
From months to minutes: The benefits of automated learning for AI annotation
Moving from manual labeling to this kind of automated learning gives you some huge advantages:
- Speed: You can get up and running in minutes. The self-serve setup of a tool like eesel AI is a world away from the months-long timeline of a typical annotation project.
- Relevance: The AI is trained on your unique customer conversations and internal docs. This makes it far more accurate and aware of your business context than a generic AI trained on random data from the internet.
- Confidence: Before the AI ever speaks to a real customer, you can run simulations in eesel AI to see how it would have handled thousands of your past tickets. This gives you a no-risk way to check its performance, see what your resolution rate would be, and make adjustments before going live.
Choosing the right AI annotation approach for your support team
The choice is becoming clearer every day. While manual annotation used to be the only game in town, today it's often a huge and unnecessary hurdle. Here’s a quick breakdown of how the different approaches compare:
| Feature | Manual Annotation | Outsourced Service | Automated Platform (eesel AI) |
|---|---|---|---|
| Time to Launch | Months to years | Weeks to months | Minutes to hours |
| Cost | High (salaries, overhead) | Very High (service fees) | Low & predictable (SaaS subscription) |
| Scalability | Poor (manual effort) | Moderate (depends on vendor) | Excellent (learns automatically) |
| Data Relevance | Good, but static | Good, but static | Highest (learns from your live data) |
| Setup Effort | Extremely High | High | Simple Self-Serve |
Stop manual AI annotation, start solving
AI annotation is a key part of building any AI system, but how we get it done has completely changed. The era of giant, manual data labeling projects is fading, replaced by smart platforms that can learn directly from the knowledge you already have.
This change gets rid of the biggest and most expensive barrier to using AI. It allows support teams to automate away repetitive tasks, give human agents a boost with tools like an AI Copilot, and provide better customer experiences without the operational nightmare of a traditional AI project. The best AI for your business is one that actually understands your business. It's time to stop worrying about labeling data and start using that data to help your customers.
Ready to build a powerful AI support agent in minutes, not months? eesel AI learns from your past tickets and knowledge bases automatically, with no manual annotation needed. Start your free trial today and see how it works.
Frequently asked questions
For most teams, yes. Modern platforms that learn directly from your helpdesk history and knowledge docs are significantly faster and more cost-effective. Manual labeling is becoming a slow and unnecessary step.
It's about consistency and scale. An automated system analyzes all your historical data and successful resolutions at once, avoiding the human subjectivity and errors that happen when different people label the same data differently.
The most common mistake is underestimating the time and cost. Teams often assume it's a quick task, but it quickly becomes a months-long project requiring constant management and quality control, which delays the actual AI launch.
For the most part, no. The system continuously learns from your new support tickets and updated knowledge docs, so you don't have a static dataset that needs constant re-labeling. You can focus on improving your knowledge base instead of labeling data.
This is a valid concern. However, by learning from thousands of tickets and cross-referencing information with official knowledge docs, the AI can identify and rely on the most objective and consistent patterns, which helps reduce the impact of biased one-off interactions.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.