The "brain" of any AI support agent is its knowledge base. How you feed information to that brain, a process called knowledge ingestion, is pretty much the most important step in getting accurate, helpful, and human-like answers. If you nail it, your AI is a star performer. If you get it wrong, you’ve just built a very expensive, very frustrating chatbot.
Ada is a big name in the AI customer service space, especially among enterprise companies. So, how do they handle this critical first step?
This guide will give you a clear, no-fluff look at the Ada Knowledge Ingestion process. We'll break down how it works, what it does well, and some potential limitations you should be aware of before you go all in.
What is Ada?
Ada is an AI-powered platform built to automate customer support conversations. You’ll often see it used by larger companies in e-commerce, finance, and tech. Its main job is to help businesses build and use conversational AI agents (or chatbots) that can talk to customers on different channels and hopefully solve their problems without needing a human.
Understanding knowledge ingestion for AI agents
So, what exactly is "knowledge ingestion"? Just think of it as the process of gathering up all your company's information, processing it, and organizing it so an AI agent can actually use it to answer questions.
It’s like giving a new employee an open-book test. The better their notes and resources (the knowledge base), the better they'll do. The whole thing is powered by a technology called Retrieval-Augmented Generation (RAG), which is a fancy way of saying the AI can look through its "notes" before it comes up with an answer.
graph TD A[Start: Customer Asks Question] --> B{AI Agent Receives Query}; B --> C[Step 1: Connecting Sources AI accesses connected knowledge bases like help centers, docs, websites]; C --> D[Step 2: Processing Content AI breaks down large documents into smaller, manageable chunks]; D --> E[Step 3: Indexing AI uses a searchable map to find the most relevant information chunks]; E --> F[AI Generates Answer]; F --> G[End: Customer Receives Answer];
style A fill:#f9f,stroke:#333,stroke-width:2px style G fill:#f9f,stroke:#333,stroke-width:2px
It typically boils down to three main parts:
-
Connecting Sources: This is where you point the AI to your information, whether that’s a help center, a folder of documents, or a website.
-
Processing Content: The AI takes all those big documents and breaks them into smaller, more manageable chunks it can actually make sense of.
-
Indexing: Finally, it builds a searchable "map" of all that information. When a question comes in, it can use this map to find the right answer in a flash.
How simple and flexible this whole process is has a huge impact on how fast you can get a genuinely helpful AI agent up and running.
How Ada Knowledge Ingestion works
Ada has a few specific ways it takes in knowledge, mostly focused on structured content that already lives in a help desk. Let's look at their methods.
Connecting to pre-built knowledge base integrations
Ada's main way of getting knowledge is by plugging into established help desk platforms where you probably already have a knowledge base. Their documentation mentions several pre-built integrations, including Zendesk, Salesforce, Contentful, Dixa, and Gladly.
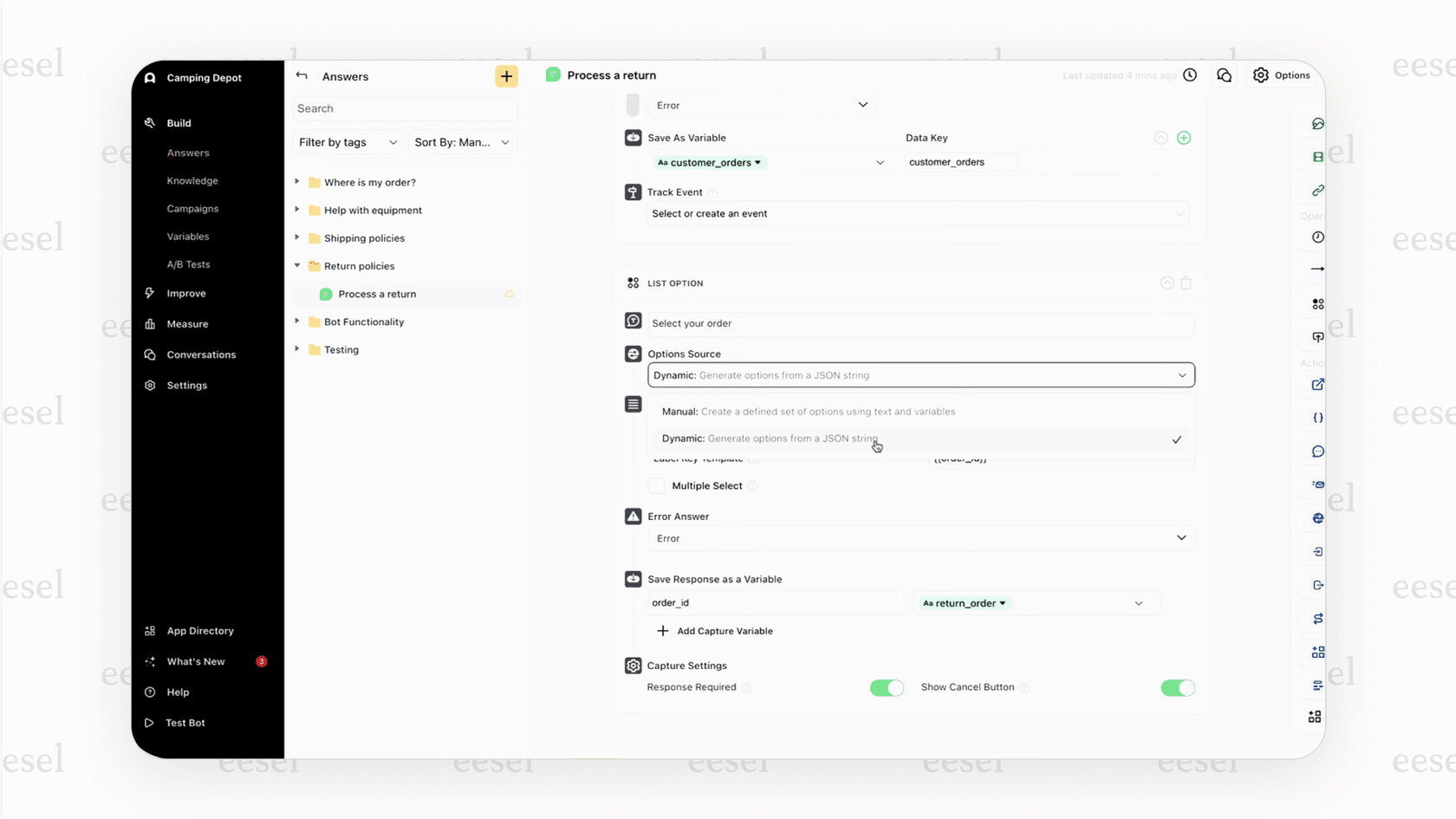
The setup usually involves logging into the Ada dashboard, picking your tool, and plugging in your credentials, like an API key or subdomain. After that, you tweak a few settings, and Ada starts pulling in your articles.
But there are a couple of catches. According to their own docs, this process often needs your knowledge base to be public (not hidden behind a login). It can also hinge on your help center using the platform's default URL structure. If your company has a custom setup, you might hit a wall here.
Using the Knowledge API for custom sources
What if your knowledge isn't sitting in Zendesk or Salesforce? For pretty much any other data source, Ada asks you to use their Knowledge API.
An API is great for flexibility, but it’s a developer-first solution. This means you’ll need an engineer on your team to write code to build, and more importantly, maintain a custom connection. If you want to connect something as simple as a collection of Google Docs, you're suddenly looking at a mini engineering project.
This is where the platform starts to feel a bit dated. Newer tools are offering self-serve, no-code integrations for a much wider variety of sources. For example, a platform like eesel AI lets anyone on your team connect knowledge from places like Google Docs or Confluence with just a few clicks, no coding degree required.
Data syncing and content requirements
Once you're connected, Ada’s system syncs with your knowledge bases every so often. For Zendesk and Salesforce, it’s about every 15 minutes. For others like Dixa or Gladly, it can stretch to as long as every six hours. That means your AI might not have the latest info if you’ve just published a critical update.
Ada also suggests using clean, logically structured content. While that’s good advice for any AI, it hints that you might have to spend a good amount of time rewriting and prepping your existing documents before they can be used effectively. That’s another manual step added to the list.
Key limitations of the Ada ingestion model
While Ada’s approach works, it has some significant limitations that can affect the quality of your AI support and how quickly you can get it launched.
Limited support for unstructured knowledge
Ada’s model really leans on perfectly structured, pre-written knowledge base articles. But think about it: where does your most valuable support knowledge actually live? It's probably buried in past support tickets, in the thousands of real-world conversations where your best agents have already solved your customers' toughest problems.
Ada’s ingestion process doesn't have a built-in way to learn from this messy, unstructured goldmine of information. All that valuable context, your brand's unique voice, and your team's proven solutions get left behind. Your AI starts from a place of theory, not real-world practice.
This is a huge missed opportunity. A more modern platform like eesel AI can train directly on your historical help desk tickets from day one. It automatically picks up your brand's tone, understands the subtle details of real customer issues, and finds solutions that have actually worked before. It’s the difference between an AI that just reads from a manual and one that sounds like your best agent.
A manual and rigid setup process
Connecting each source in Ada involves a specific, multi-step setup that can be a bit finicky. If you use a tool that isn't on their short list of integrations, you're immediately pushed into a development project with their API.
This creates a rigid system where you have to bend your tools and workflows to fit the platform, rather than the other way around. It slows things down and creates a reliance on technical folks that many support teams just don't have on standby.
In contrast, eesel AI offers a super simple, self-serve experience. You can connect your help desk and other knowledge sources with one-click integrations and go live in minutes, not months. The idea is to slide into your existing workflow without causing a major headache.
Lack of risk-free testing
After you’ve gone through all the trouble of setting up your knowledge ingestion, the big question is: "How will this AI actually do with real customer questions?"
Ada's documentation doesn't talk about a simulation tool that lets you test the AI's performance on your past tickets before you let it talk to customers. This means you have to go live with a lot of uncertainty, basically flipping a switch and hoping for the best. You're testing in production, which is a risky game to play when customer satisfaction is on the line.
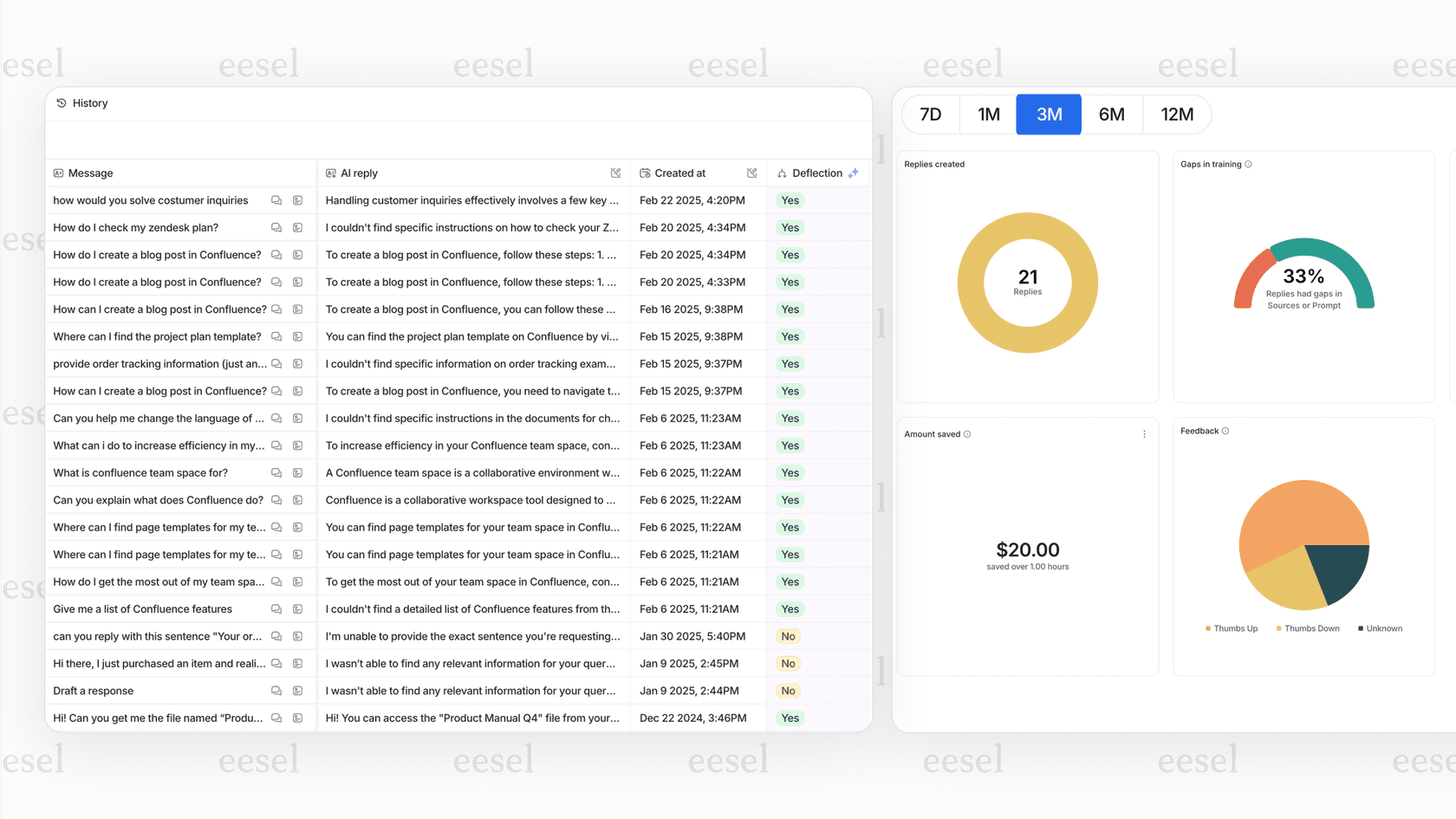
This is another spot where newer platforms have moved ahead. For instance, eesel AI's simulation mode lets you safely test your AI on thousands of past tickets in a private sandbox. It gives you a solid forecast of its resolution rate, shows you exactly how it will answer different questions, and helps you spot any knowledge gaps. You can build total confidence and tweak its behavior before a single customer ever chats with it.
Pricing
Ada's pricing isn't listed on their website. This is pretty normal for enterprise software, but it means you have to get in touch with their sales team to get a quote.
The main drawback here is that you might go through a long sales process just to find out if it even fits your budget. The costs can also be hard to predict, as they might be tied to things like ticket volume or the number of resolutions, which can change from month to month.
For teams that prefer a bit more transparency, other platforms have clear and predictable pricing. For example, eesel AI’s plans are public and easy to understand.
| Plan | Monthly Price (Billed Monthly) | Key Features |
|---|---|---|
| Team | $299 | Train on websites/docs, Slack integration, AI Copilot |
| Business | $799 | Everything in Team + train on past tickets, custom AI Actions, bulk simulation |
| Custom | Contact Sales | Advanced integrations, multi-agent orchestration, custom controls |
A key detail here is that eesel AI's pricing is based on a set number of AI interactions each month, with no extra fees per resolution. Your bill won't suddenly jump just because you had a busy support month. Plus, with flexible monthly plans, you can start small and cancel anytime without being locked into a long-term contract.
A better alternative: Flexible knowledge ingestion with eesel AI
While Ada is a solid platform, its knowledge ingestion model can feel a bit stiff, developer-heavy, and it doesn't offer a safe way to test before you launch. For teams that need to move fast and stay flexible, there’s a better way.
eesel AI is the modern alternative, built for speed, flexibility, and confidence. It gives you a much more intuitive and powerful way to build your AI’s brain.
Title: Knowledge Ingestion: Ada vs. eesel AI Ada Side:
-
Icon for limited sources (Help desks like Zendesk, Salesforce).
-
Icon for API, labeled "Requires Developers for custom sources."
-
Icon for slow sync, labeled "Syncs every 15 mins to 6 hours."
-
Icon for no testing, labeled "No risk-free simulation mode." eesel AI Side:
-
Icons for multiple sources (Help desks, Confluence, Google Docs, etc.), labeled "Dozens of no-code integrations."
-
Icon for self-serve, labeled "Anyone can connect sources in minutes."
-
Icon for real-time sync, labeled "Learns from real-time data."
-
Icon for simulation, labeled "Test safely on past tickets before launch."
Here’s a quick rundown of the difference:
-
Connect everything without the headache: Instantly hook up help centers, past tickets, Confluence, Google Docs, and dozens of other sources, no code needed.
-
Go live in minutes, not months: It's a truly self-serve platform. You can sign up, connect your tools, and have a working AI agent ready to go in minutes, without ever talking to a salesperson.
-
Learn from your team's best work: The AI automatically analyzes past ticket resolutions, so its answers are based on what has actually worked for your customers.
-
Test with total confidence: Use the simulation mode to see how well it will perform and get a clear forecast of your ROI before you turn it on for customers.
Getting knowledge ingestion right
Getting knowledge ingestion right is the foundation of any good AI support strategy. It needs to be simple enough for anyone on the team to manage, powerful enough to pull in all your knowledge, and flexible enough to grow with you.
While traditional platforms like Ada offer a structured but often clunky approach, modern solutions like eesel AI deliver the speed, flexibility, and smart learning that today's support teams really need. By automating the heavy lifting and giving you the tools to launch with confidence, you can stop spending months on setup and start seeing results in days.
Ready to see what a truly seamless knowledge ingestion process looks like? Give eesel AI a try.
Frequently asked questions
Ada Knowledge Ingestion primarily connects via pre-built integrations with popular help desk platforms like Zendesk, Salesforce, and Contentful. You typically log into the Ada dashboard, select your platform, and input credentials. This process then allows Ada to pull in your existing knowledge base articles.
If your knowledge isn't in a pre-integrated platform, Ada requires you to use its Knowledge API. This means your team will need an engineer to write and maintain custom code to build connections, which can turn a simple task into a development project.
Yes, Ada Knowledge Ingestion heavily relies on perfectly structured, pre-written knowledge base articles. It lacks a built-in way to learn from unstructured data sources, such as historical support tickets, which often contain valuable real-world solutions.
Ada Knowledge Ingestion syncs data from connected knowledge bases at varying intervals. For platforms like Zendesk and Salesforce, it's about every 15 minutes, while for others like Dixa or Gladly, it can take up to six hours. This means your AI might not always have the absolute latest information immediately after an update.
Ada's documentation does not mention a built-in simulation tool to test the AI's performance on past tickets before deployment. This means you typically launch with some uncertainty, essentially testing in a live production environment with real customers.
The setup for Ada Knowledge Ingestion is often a multi-step process, especially if you need to use their API for non-standard sources, which requires developer involvement. This can make the process rigid, requiring your workflows to adapt to Ada's structure rather than the other way around.
Share this article

Article by
Kenneth Pangan
Writer and marketer for over ten years, Kenneth Pangan splits his time between history, politics, and art with plenty of interruptions from his dogs demanding attention.


